Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
Fast Clustering Using Adaptive Density Peak DetectionDescriptionClustering of data by finding cluster centers from estimated density peaks. It is a non-iterative procedure that incorporates multivariate Gaussian density estimation. The number of clusters as well as bandwidths can either be selected by the user or selected automatically through an internal clustering criterion. Usageadpclust(dat, h = NULL, htype = "AMISE", nclust = 2:10, centroids = "auto", ac = 1, f.cut = 0.1, fdelta = "mnorm", mycols = NULL, dmethod = "euclidean", verbose = FALSE, draw = TRUE, findSil = TRUE) Arguments
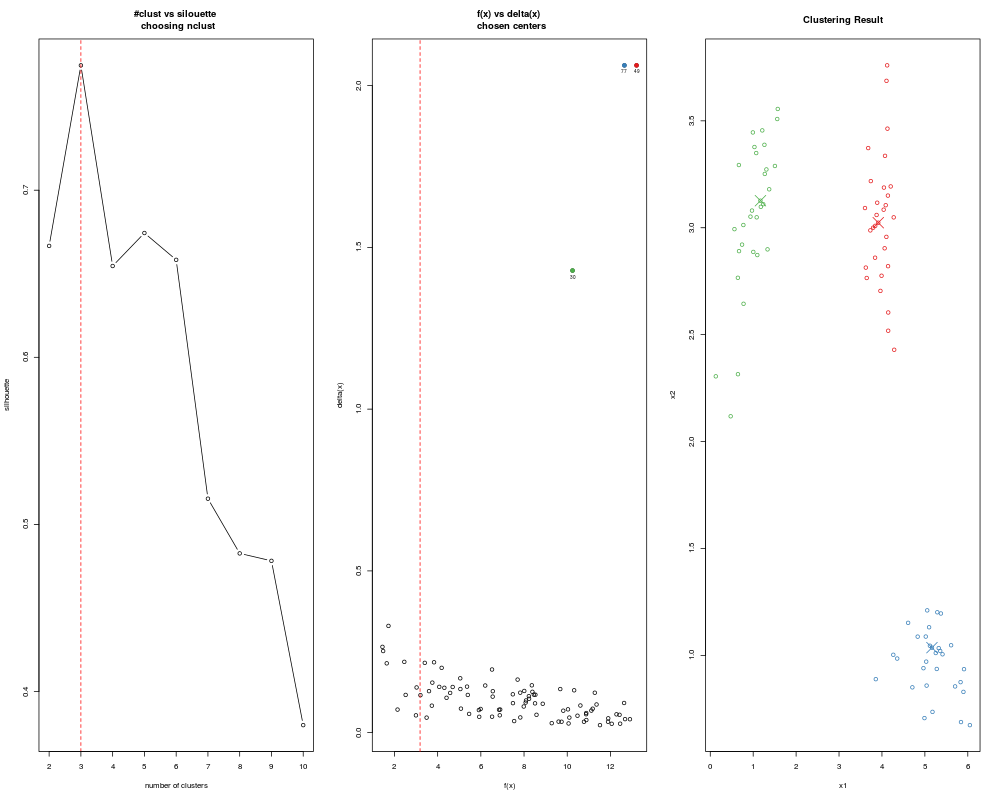
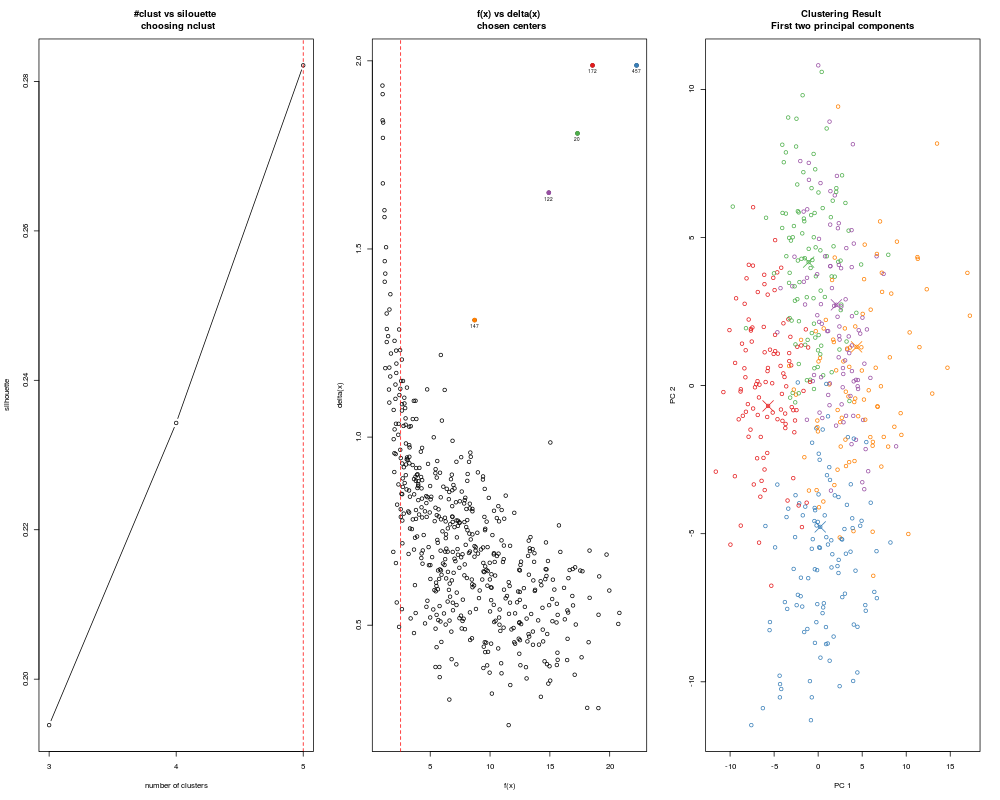
DetailsGiven n data points in p dimensions, adpclust() first finds local density estimation f(x) of each data point x. The bandwidth h used in density estimation can either be explicitly specified by user through the argument 'h', or automatically selected from a range of testing values. In the case of automatic selection of bandwidths, first a reference bandwidth h0 is calculated by one of the two methods: Scott's Rule-of-Thumb value (htype = "ROT") or Wand's Asymptotic-Mean-Integrated-Squared-Error value (htype = "AMISE"), then 10 values equally spread in the range [1/3h0, 3h0] are tested. For each data point x, adpclust() also finds an 'isolation' index delta(x), which is defined as the distance between x and the closest point y with f(y) > f(x). The scatter plot (f(x), delta(x)) is called the decision plot. For an appropriate h, cluster centroids appear in the upper-right corner of the decision plot, i.e. points with large f(x) and delta(x). After centroids are picked from the decision plot either by user (centroids = 'user') or automatically (centroids = "auto"), other data points are clustered to the cluster marked by the closest centroid. When centroids = 'user', the decision plot is generated and displayed on screen. The user selects centroids by clicking the points on the upper right corner of the decision plot. A right click or ESC ends the selection. ValueAn 'adpclust' object, which contains the list of the following items.
References
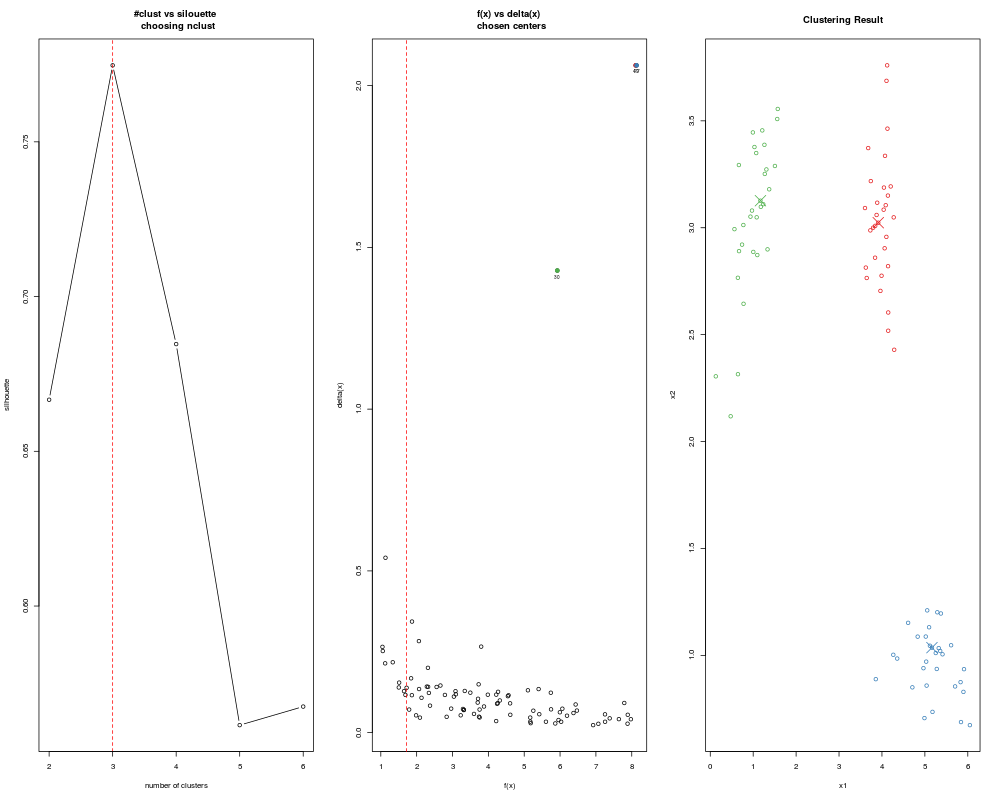
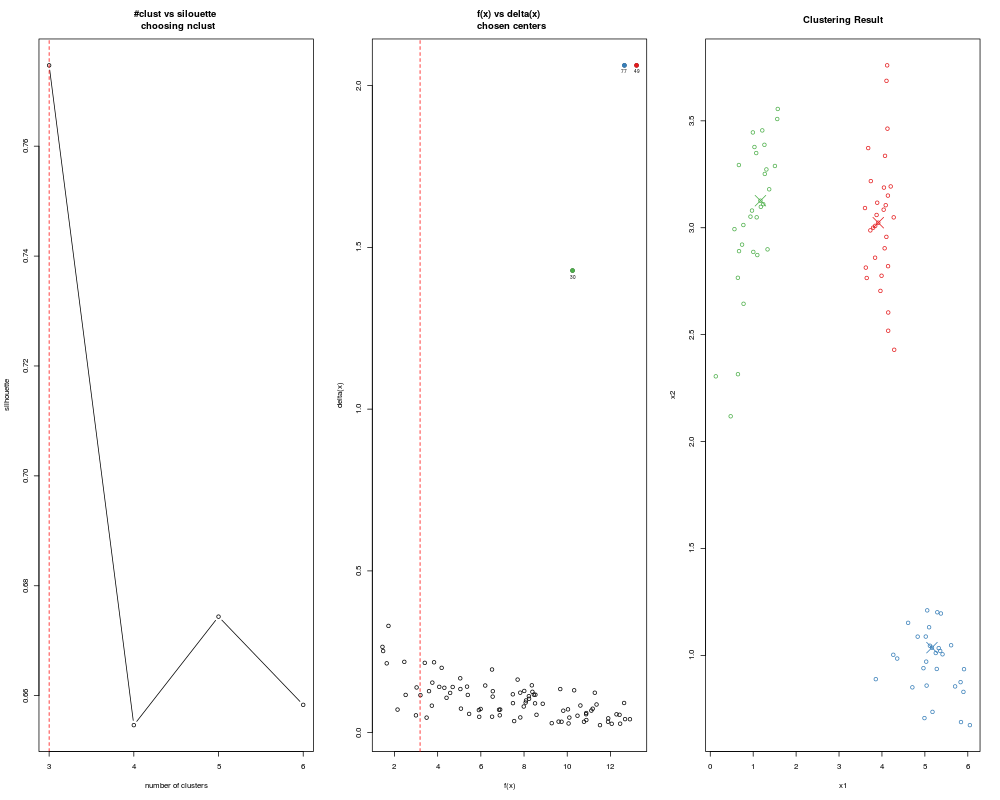
Examples## Load a data set with 3 clusters data(clust3) ## Automatically select cluster centroids ans <- adpclust(clust3, centroids = "auto", draw = FALSE) summary(ans) plot(ans) ## Specify the grid of h and nclust ans <- adpclust(clust3, centroids = "auto", h = c(0.1, 0.2, 0.3), nclust = 2:6) ## Specify that bandwidths should be searched around ## Wand's Asymptotic-Mean-Integrated-Squared-Error bandwidth ## Also test 3 to 6 clusters. ans <- adpclust(clust3, centroids = "auto", htype = "AMISE", nclust = 3:6) ## Set a specific bandwidth value. ans <- adpclust(clust3, centroids = "auto", h = 5) ## Change method of automatic selection of centers ans <- adpclust(clust3, centroids = "auto", nclust = 2:6, ac = 2) ## Specify that the single "ROT" bandwidth value by ## using the 'ROT()' function ans <- adpclust(clust3, centroids = "auto", h = ROT(clust3)) ## Set single h and nclust. Do not calculate silhouette to speed things up ans <- adpclust(clust3, centroids = "auto", h = ROT(clust3), nclust = 3, findSil = FALSE) ## Centroids selected by user ## Not run: ans <- adpclust(clust3, centroids = "user", h = ROT(clust3)) ## End(Not run) ## A larger data set data(clust5) ans <- adpclust(clust5, centroids = "auto", htype = "ROT", nclust = 3:5) summary(ans) plot(ans) Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(ADPclust)
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/ADPclust/ADPclust.Rd_%03d_medium.png", width=480, height=480)
> ### Name: adpclust
> ### Title: Fast Clustering Using Adaptive Density Peak Detection
> ### Aliases: adpclust
>
> ### ** Examples
>
> ## Load a data set with 3 clusters
> data(clust3)
>
> ## Automatically select cluster centroids
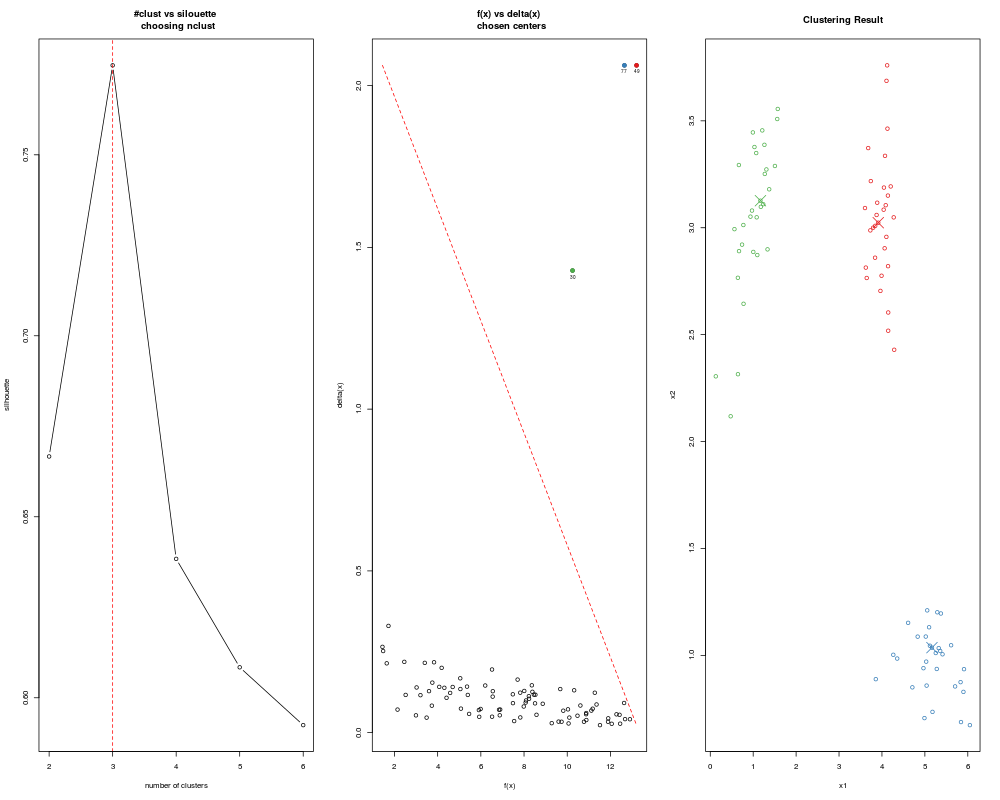
> ans <- adpclust(clust3, centroids = "auto", draw = FALSE)
> summary(ans)
-- ADPclust Procedure --
Number of variables: 2
Number of obs.: 90
Centroids selection: Automatic
Bandwith selection: AMISE (0.16)
Number of clusters: 3
Avg. Silhouette: 0.7747114
f(x):
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.444 5.048 7.907 7.599 10.300 13.210
delta(x):
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.02322 0.05521 0.09144 0.15980 0.13480 2.06300
> plot(ans)
>
> ## Specify the grid of h and nclust
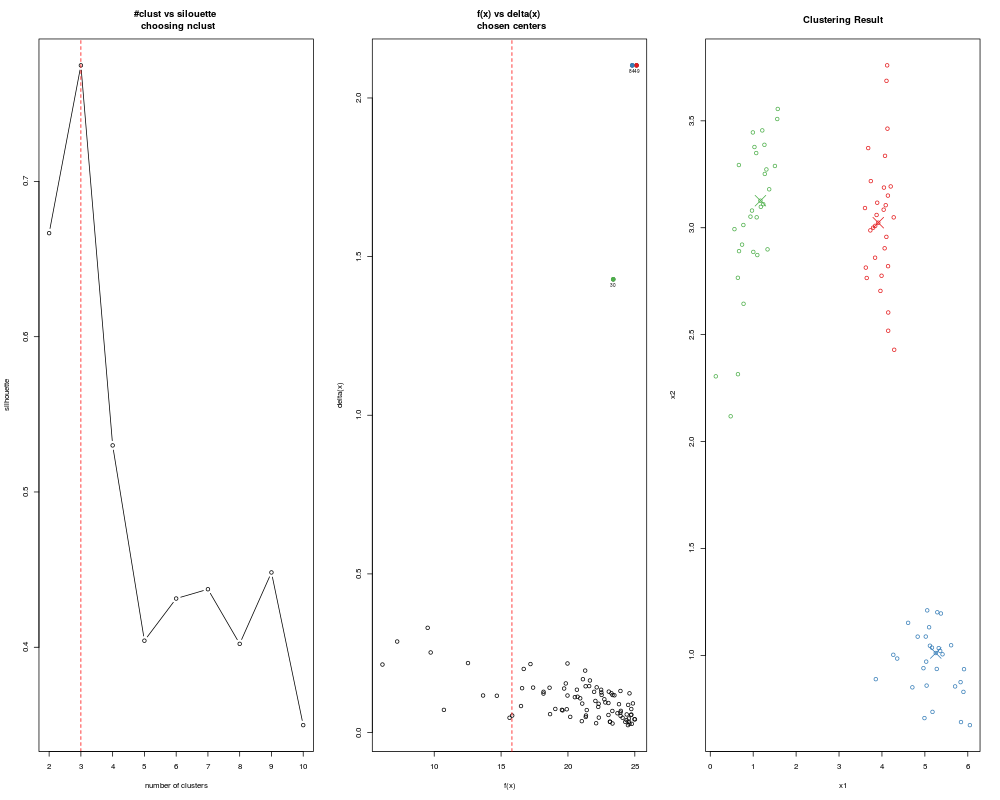
> ans <- adpclust(clust3, centroids = "auto", h = c(0.1, 0.2, 0.3), nclust = 2:6)
>
> ## Specify that bandwidths should be searched around
> ## Wand's Asymptotic-Mean-Integrated-Squared-Error bandwidth
> ## Also test 3 to 6 clusters.
> ans <- adpclust(clust3, centroids = "auto", htype = "AMISE", nclust = 3:6)
>
> ## Set a specific bandwidth value.
> ans <- adpclust(clust3, centroids = "auto", h = 5)
>
> ## Change method of automatic selection of centers
> ans <- adpclust(clust3, centroids = "auto", nclust = 2:6, ac = 2)
>
> ## Specify that the single "ROT" bandwidth value by
> ## using the 'ROT()' function
> ans <- adpclust(clust3, centroids = "auto", h = ROT(clust3))
>
> ## Set single h and nclust. Do not calculate silhouette to speed things up
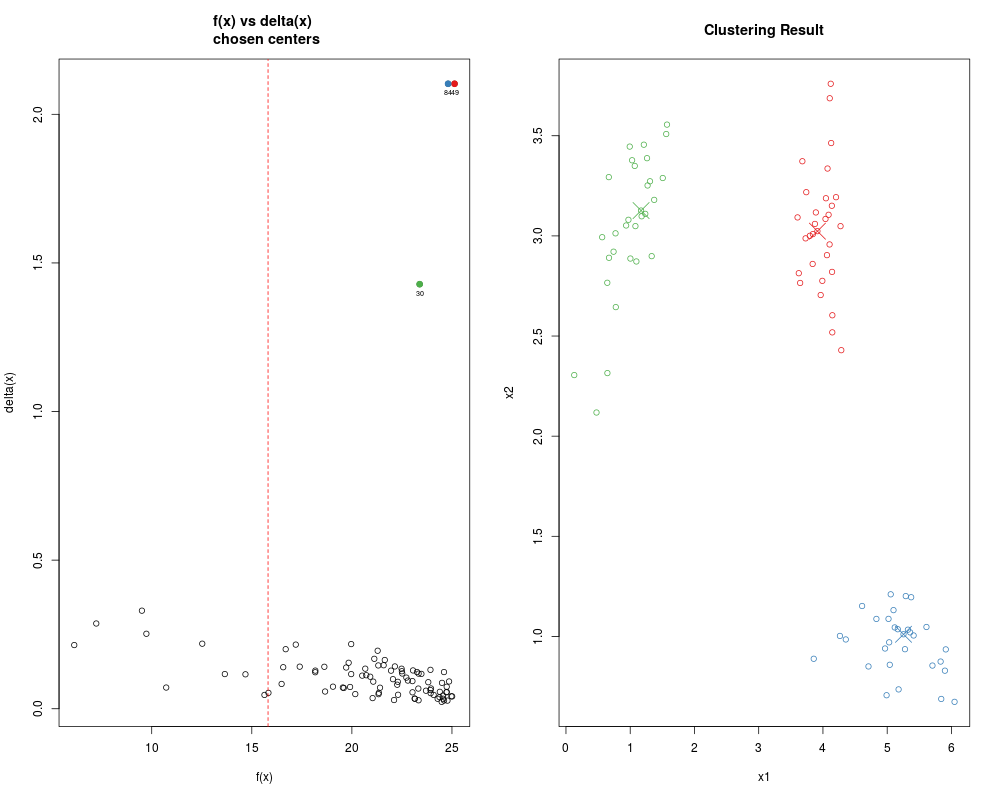
> ans <- adpclust(clust3, centroids = "auto", h = ROT(clust3), nclust = 3, findSil = FALSE)
>
> ## Centroids selected by user
> ## Not run:
> ##D ans <- adpclust(clust3, centroids = "user", h = ROT(clust3))
> ## End(Not run)
>
> ## A larger data set
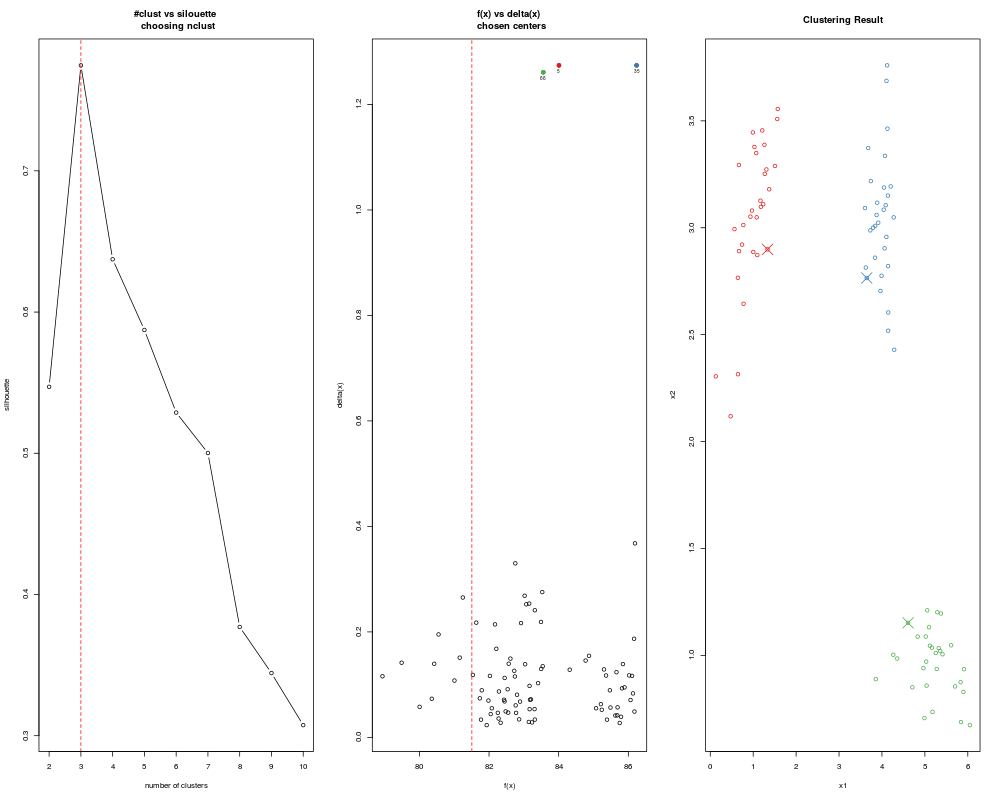
> data(clust5)
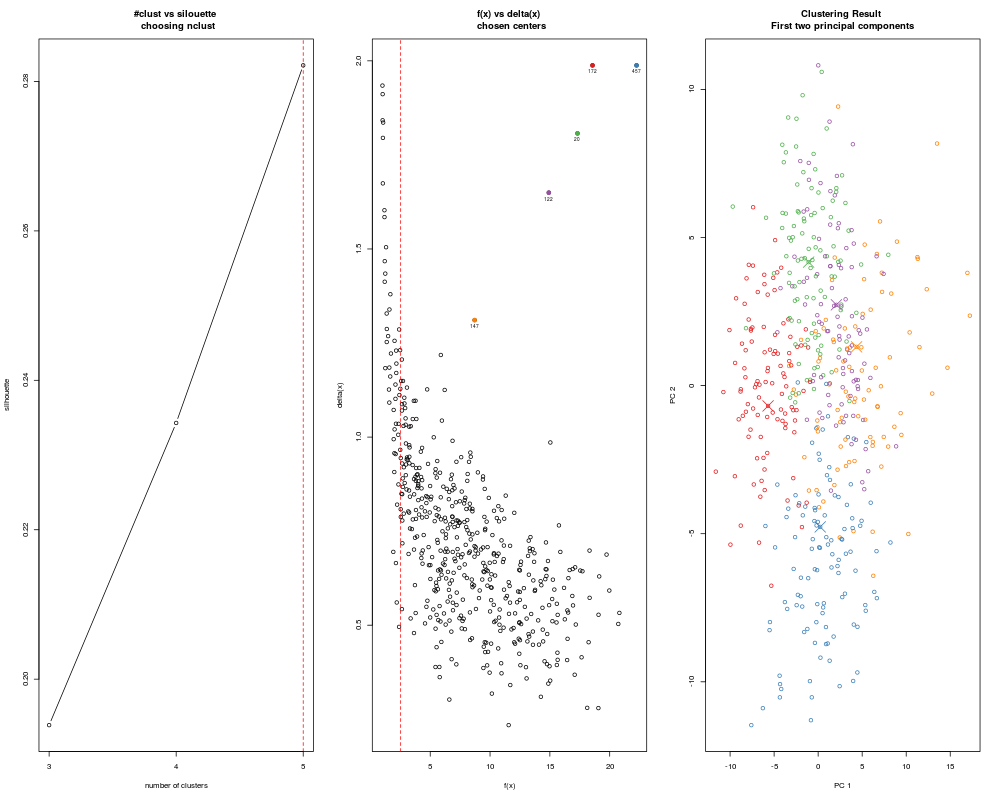
> ans <- adpclust(clust5, centroids = "auto", htype = "ROT", nclust = 3:5)
> summary(ans)
-- ADPclust Procedure --
Number of variables: 5
Number of obs.: 500
Centroids selection: Automatic
Bandwith selection: ROT (0.61)
Number of clusters: 5
Avg. Silhouette: 0.2821572
f(x):
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.009 4.186 7.208 8.012 11.090 22.240
delta(x):
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2344 0.5645 0.6985 0.7513 0.8686 1.9880
> plot(ans)
>
>
>
>
>
> dev.off()
null device
1
>
|