either a matrix, data.frame, a object of class
"amelia", or an object of class "molist". The first two will call the default S3 method. The third
a convenient way to perform more imputations with the same
parameters. The fourth will impute based on the settings from
moPrep and any additional arguments.
m
the number of imputed datasets to create.
p2s
an integer value taking either 0 for no screen output, 1 for normal screen printing of iteration
numbers, and 2 for detailed screen output. See "Details" for
specifics on output when p2s=2.
frontend
a logical value used internally for the GUI.
idvars
a vector of column numbers or column names that indicates identification variables. These will be dropped from the analysis but copied into the imputed datasets.
ts
column number or variable name indicating the variable identifying time in time series data.
cs
column number or variable name indicating the cross section variable.
polytime
integer between 0 and 3 indicating what
power of polynomial should be included in the imputation model
to account for the effects of time. A setting of 0 would
indicate constant levels, 1 would indicate linear time
effects, 2 would indicate squared effects, and 3 would
indicate cubic time effects.
splinetime
interger value of 0 or greater to control cubic
smoothing splines of time. Values between 0 and 3 create a simple
polynomial of time (identical to the polytime argument). Values k greater
than 3 create a spline with an additional k-3
knotpoints.
intercs
a logical variable indicating if the
time effects of polytime should vary across the
cross-section.
lags
a vector of numbers or names indicating columns in the data
that should have their lags included in the imputation model.
leads
a vector of numbers or names indicating columns in the data
that should have their leads (future values) included in the imputation
model.
startvals
starting values, 0 for the parameter matrix from
listwise deletion, 1 for an identity matrix.
tolerance
the convergence threshold for the EM algorithm.
logs
a vector of column numbers or column names that refer
to variables that require log-linear transformation.
sqrts
a vector of numbers or names indicating columns in the data
that should be transformed by a sqaure root function. Data in this
column cannot be less than zero.
lgstc
a vector of numbers or names indicating columns in the data
that should be transformed by a logistic function for proportional data.
Data in this column must be between 0 and 1.
noms
a vector of numbers or names indicating columns in the data
that are nominal variables.
ords
a vector of numbers or names indicating columns in the
data that should be treated as ordinal variables.
incheck
a logical indicating whether or not the inputs to the
function should be checked before running amelia. This should
only be set to FALSE if you are extremely confident that your
settings are non-problematic and you are trying to save computational
time.
collect
a logical value indicating whether or
not the garbage collection frequency should be increased during the imputation model. Only set this to TRUE if you are experiencing memory
issues as it can significantly slow down the imputation
process.
arglist
an object of class "ameliaArgs" from a previous run of
Amelia. Including this object will use the arguments from that run.
empri
number indicating level of the empirical (or ridge) prior.
This prior shrinks the covariances of the data, but keeps the means
and variances the same for problems of high missingness, small N's or
large correlations among the variables. Should be kept small,
perhaps 0.5 to 1 percent of the rows of the data; a
reasonable upper bound is around 10 percent of the rows of the
data.
priors
a four or five column matrix containing the priors for
either individual missing observations or variable-wide missing
values. See "Details" for more information.
autopri
allows the EM chain to increase the empirical prior if
the path strays into an nonpositive definite covariance matrix, up
to a maximum empirical prior of the value of this argument times
$n$, the number of observations. Must be between 0 and 1, and at
zero this turns off this feature.
emburn
a numeric vector of length 2, where emburn[1] is
a the minimum EM chain length and emburn[2] is the
maximum EM chain length. These are ignored if they are less than 1.
bounds
a three column matrix to hold logical bounds on the
imputations. Each row of the matrix should be of the form
c(column.number, lower.bound,upper.bound) See Details below.
max.resample
an integer that specifies how many times Amelia
should redraw the imputed values when trying to meet the logical
constraints of bounds. After this value, imputed values are
set to the bounds.
overimp
a two-column matrix describing which cells are to be
overimputed. Each row of the matrix should be a c(row,
column) pair. Each of these cells will be treated as missing and
replaced with draws from the imputation model.
boot.type
choice of bootstrap, currently restricted to either
"ordinary" for the usual non-parametric bootstrap and
"none" for no bootstrap.
parallel
the type of parallel operation to be used (if any). If
missing, the default is taken from the option
"amelia.parallel" (and if that is not set, "no").
ncpus
integer: the number of processes to be used in parallel
operation: typically one would choose the number of available CPUs.
cl
an optional parallel or snow cluster for use if
parallel = "snow". If not supplied, a cluster on the local
machine is created for the duration of the amelia call.
...
further arguments to be passed.
Details
Multiple imputation is a method for analyzing incomplete
multivariate data. This function will take an incomplete dataset in
either data frame or matrix form and return m imputed datatsets
with no missing values. The algorithm first bootstraps a sample dataset
with the same dimensions as the original data, estimates the sufficient statistics (with priors if specified) by EM, and then imputes the missing
values of sample. It repeats this process m times to produce
the m complete datasets where the observed values are the same and the unobserved values are drawn from their posterior distributions.
The function will start a "fresh" run of the algorithm if x is
either a incomplete matrix or data.frame. In this method, all of the
options will be user-defined or set to their default. If x the output of
a previous Amelia run (that is, an object of class "amelia"), then
Amelia will run with the options used in that previous run. This is a
convenient way to run more imputations of the same model.
You can provide Amelia with informational priors about the missing
observations in your data. To specify priors, pass a four or five
column matrix to the priors argument with each row specifying a
different priors as such:
So, in the first and second column of the priors matrix should be the
row and column number of the prior being set. In the other columns
should either be the mean and standard deviation of the prior, or a
minimum, maximum and confidence level for the prior. You must specify
your priors all as distributions or all as confidence ranges. Note
that ranges are converted to distributions, so setting a confidence of
1 will generate an error.
Setting a priors for the missing values of an entire variable is done
in the same manner as above, but inputing a 0 for the row
instead of the row number. If priors are set for both the entire
variable and an individual observation, the individual prior takes
precedence.
In addition to priors, Amelia allows for logical bounds on
variables. The bounds argument should be a matrix with 3
columns, with each row referring to a logical bound on a variable. The
first column should be the column number of the variable to be
bounded, the second column should be the lower bounds for that
variable, and the third column should be the upper bound for that
variable. As Amelia enacts these bounds by resampling, particularly
poor bounds will end up resampling forever. Amelia will stop
resampling after max.resample attempts and simply set the
imputation to the relevant bound.
If each imputation is taking a long time to converge, you can increase
the empirical prior, empri. This value has the effect of smoothing
out the likelihood surface so that the EM algorithm can more easily find
the maximum. It should be kept as low as possible and only used if needed.
Amelia assumes the data is distributed multivariate normal. There are a
number of variables that can break this assumption. Usually, though, a
transformation can make any variable roughly continuous and unbounded.
We have included a number of commonly needed transformations for data.
Note that the data will not be transformed in the output datasets and the
transformation is simply useful for climbing the likelihood.
Amelia can run its imputations in parallel using the methods of the
parallel package. The parallel argument names the
parallel backend that Amelia should use. Users on Windows systems must
use the "snow" option and users on Unix-like systems should use
"multicore". The multicore backend sets itself up
automatically, but the snow backend requires more setup. You
can pass a predefined cluster from the
parallel::makePSOCKcluster function to the cl
argument. Without this cluster, Amelia will attempt to create a
reasonable default cluster and stop it once computation is
complete. When using the parallel backend, users can set the number of
CPUs to use with the ncpus argument. The defaults for these two
arguments can be set with the options "amelia.parallel" and
"amelia.ncpus".
Please refer to the Amelia manual for more information on the function
or the options.
Value
An instance of S3 class "amelia" with the following objects:
imputations
a list of length m with an imputed dataset in
each entry. The class (matrix or data.frame) of these entries will
match x.
m
an integer indicating the number of imputations run.
missMatrix
a matrix identical in size to the original dataset
with 1 indicating a missing observation and a 0 indicating an observed
observation.
theta
An array with dimensions (p+1) by (p+1) by m (where
p is the number of variables in the imputations model) holding
the converged parameters for each of the m EM chains.
mu
A p by m matrix of of the posterior modes for the
complete-data means in each of the EM chains.
covMatrices
An array with dimensions (p) by (p) by
m where the first two dimensions hold the posterior modes of the
covariance matrix of the complete data for each of the EM chains.
code
a integer indicating the exit code of the Amelia run.
message
an exit message for the Amelia run
iterHist
a list of iteration histories for each EM chain. See
documentation for details.
arguments
a instance of the class "ameliaArgs" which holds the
arguments used in the Amelia run.
overvalues
a vector of values removed for overimputation. Used to
reformulate the original data from the imputations.
Note that the theta, mu and covMatrcies objects
refers to the data as seen by the EM algorithm and is thusly centered,
scaled, stacked, tranformed and rearranged. See the manual for details
and how to access this information.
Author(s)
James Honaker, Gary King, Matt Blackwell
References
Honaker, J., King, G., Blackwell, M. (2011).
Amelia II: A Program for Missing Data.
Journal of Statistical Software, 45(7), 1–47.
URL http://www.jstatsoft.org/v45/i07/.
See Also
For imputation diagnostics, missmap, compare.density,
overimpute and disperse. For time series
plots, tscsPlot. Also: plot.amelia,
write.amelia, and ameliabind.
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(Amelia)
Loading required package: Rcpp
##
## Amelia II: Multiple Imputation
## (Version 1.7.4, built: 2015-12-05)
## Copyright (C) 2005-2016 James Honaker, Gary King and Matthew Blackwell
## Refer to http://gking.harvard.edu/amelia/ for more information
##
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/Amelia/amelia.Rd_%03d_medium.png", width=480, height=480)
> ### Name: amelia
> ### Title: AMELIA: Multiple Imputation of Incomplete Multivariate Data
> ### Aliases: amelia amelia.amelia amelia.default amelia.molist
> ### Keywords: models
>
> ### ** Examples
>
> data(africa)
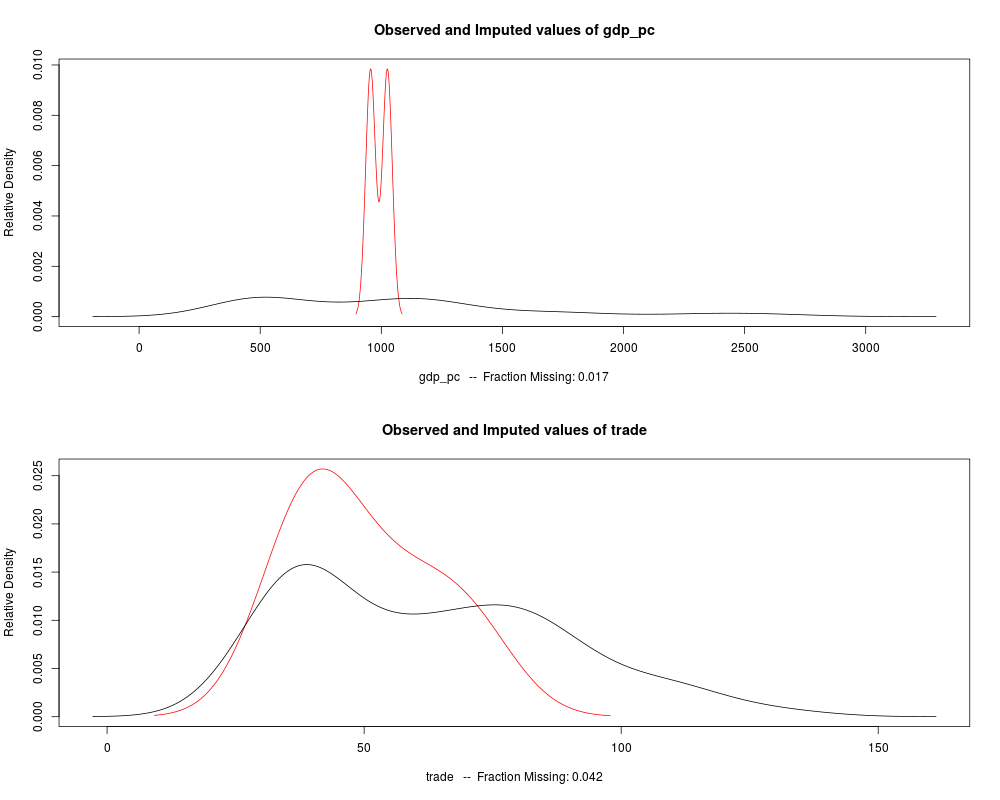
> a.out <- amelia(x = africa, cs = "country", ts = "year", logs = "gdp_pc")
-- Imputation 1 --
1 2
-- Imputation 2 --
1 2 3
-- Imputation 3 --
1 2 3
-- Imputation 4 --
1 2 3
-- Imputation 5 --
1 2
> summary(a.out)
Amelia output with 5 imputed datasets.
Return code: 1
Message: Normal EM convergence.
Chain Lengths:
--------------
Imputation 1: 2
Imputation 2: 3
Imputation 3: 3
Imputation 4: 3
Imputation 5: 2
Rows after Listwise Deletion: 115
Rows after Imputation: 120
Patterns of missingness in the data: 3
Fraction Missing for original variables:
-----------------------------------------
Fraction Missing
year 0.00000000
country 0.00000000
gdp_pc 0.01666667
infl 0.00000000
trade 0.04166667
civlib 0.00000000
population 0.00000000
> plot(a.out)
>
>
>
>
>
> dev.off()
null device
1
>
 .
.