a numeric matrix to be clustered. The columns correspond to the time-course and the rows correspond to phosphorylation sites.
annotation
a list with names correspond to kinases and elements correspond to substrates belong to each kinase.
rep
number of times the clustering is to be applied. This is to account for variability in the clustering algorithm.
kRange
the range of k to be tested for clustering.
clustAlg
the clustering algorithm to be used. The default is cmeans clustering.
effectiveSize
the size of annotation groups to be considered for calculating enrichment. Groups that are too small
or too large will be removed from calculating overall enrichment of the clustering.
pvalueCutoff
a pvalue cutoff for determining which kinase-substrate groups to be included in calculating overall enrichment of the clustering.
alpha
a penalty factor for penalizing large number of clusters.
Value
a clue output that contains the input parameters used for evaluation and the evaluation results. Use ls(x) to see details of output. 'x' be the output here.
Examples
# load the human ES phosphoprotoemics data (Rigbolt et al. Sci Signal. 4(164):rs3, 2011)
data(hES)
# load the PhosphoSitePlus annotations (Hornbeck et al. Nucleic Acids Res. 40:D261-70, 2012)
data(PhosphoSite)
# make a subset of hES dataset for demonstrating the example in a short time frame
ids <- c("CK2A1", "ERK1", "ERK2", "CDK7",
"p90RSK", "p70S6K", "PKACA", "CDK1", "DNAPK", "ATM", "CDK2")
hESs <- hES[rownames(hES) %in% unlist(PhosphoSite.human[ids]),]
# run CLUE with a repeat of 3 times and a range from 2 to 13
set.seed(2)
clueObj <- runClue(Tc=hESs, annotation=PhosphoSite.human, rep=2, kRange=13)
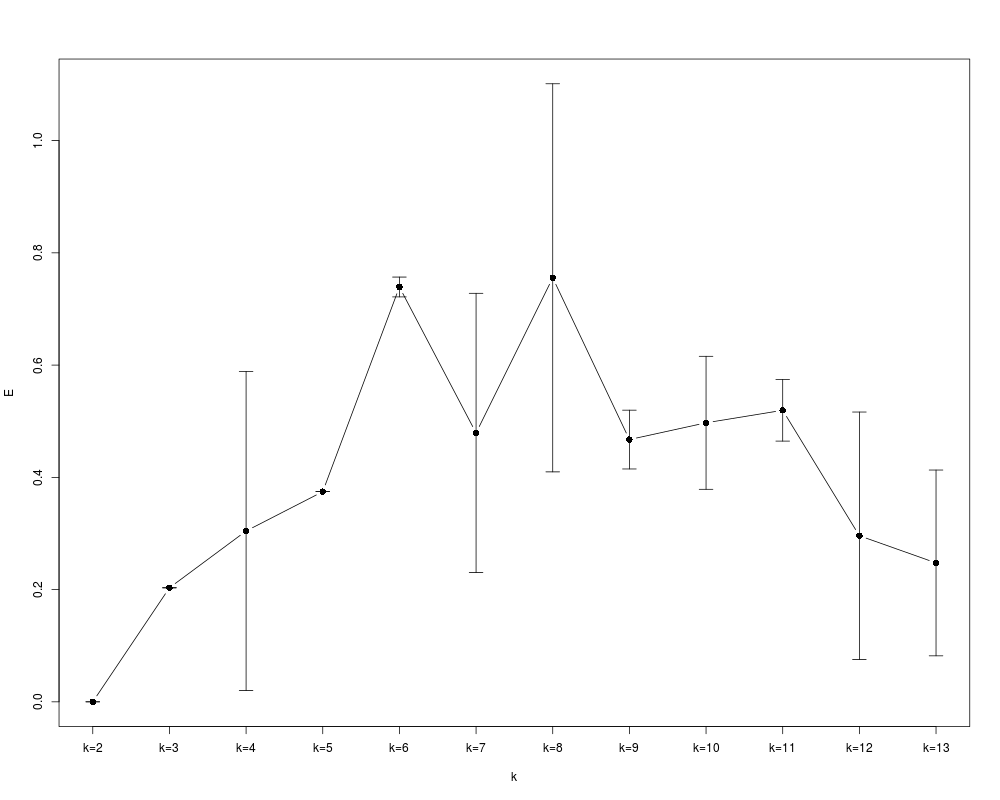
# visualize the evaluation outcome
Ms <- apply(clueObj$evlMat, 2, mean, na.rm=TRUE)
Ss <- apply(clueObj$evlMat, 2, sd, na.rm=TRUE)
library(Hmisc)
errbar(1:length(Ms), Ms, Ms+Ss, Ms-Ss, cex=1.2, type="b", xaxt="n", xlab="k", ylab="E")
axis(1, at=1:12, labels=paste("k=", 2:13, sep=""))
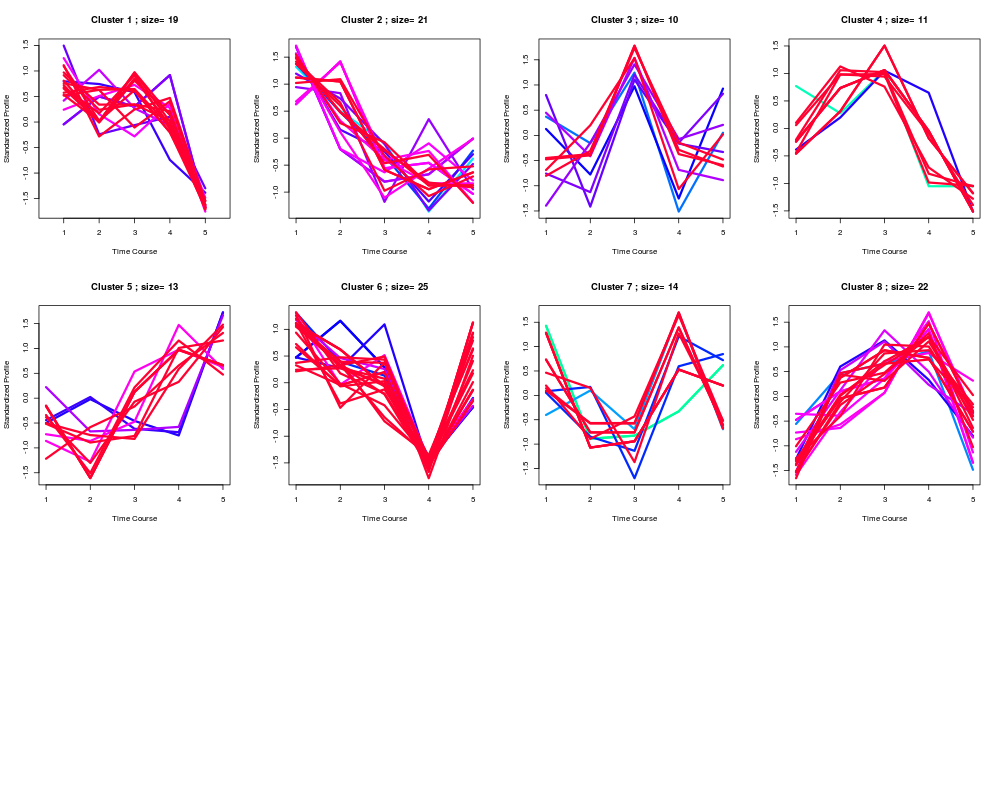
# generate the optimal clustering results
best <- clustOptimal(clueObj, rep=10, mfrow=c(3, 4))
# list enriched clusters
best$enrichList
# obtain the optimal clustering object (not run)
# best$clustObj
Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(ClueR)
Loading required package: e1071
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/ClueR/runClue.Rd_%03d_medium.png", width=480, height=480)
> ### Name: runClue
> ### Title: Run CLUster Evaluation
> ### Aliases: runClue
>
> ### ** Examples
>
> # load the human ES phosphoprotoemics data (Rigbolt et al. Sci Signal. 4(164):rs3, 2011)
> data(hES)
> # load the PhosphoSitePlus annotations (Hornbeck et al. Nucleic Acids Res. 40:D261-70, 2012)
> data(PhosphoSite)
>
> # make a subset of hES dataset for demonstrating the example in a short time frame
> ids <- c("CK2A1", "ERK1", "ERK2", "CDK7",
+ "p90RSK", "p70S6K", "PKACA", "CDK1", "DNAPK", "ATM", "CDK2")
> hESs <- hES[rownames(hES) %in% unlist(PhosphoSite.human[ids]),]
>
> # run CLUE with a repeat of 3 times and a range from 2 to 13
> set.seed(2)
> clueObj <- runClue(Tc=hESs, annotation=PhosphoSite.human, rep=2, kRange=13)
repeat 1
repeat 2
>
> # visualize the evaluation outcome
> Ms <- apply(clueObj$evlMat, 2, mean, na.rm=TRUE)
> Ss <- apply(clueObj$evlMat, 2, sd, na.rm=TRUE)
> library(Hmisc)
Loading required package: lattice
Loading required package: survival
Loading required package: Formula
Loading required package: ggplot2
Attaching package: 'Hmisc'
The following object is masked from 'package:e1071':
impute
The following objects are masked from 'package:base':
format.pval, round.POSIXt, trunc.POSIXt, units
> errbar(1:length(Ms), Ms, Ms+Ss, Ms-Ss, cex=1.2, type="b", xaxt="n", xlab="k", ylab="E")
> axis(1, at=1:12, labels=paste("k=", 2:13, sep=""))
>
> # generate the optimal clustering results
> best <- clustOptimal(clueObj, rep=10, mfrow=c(3, 4))
>
> # list enriched clusters
> best$enrichList
$`cluster 1`
kinase pvalue size
[1,] "CDK7" "0.00141500579716477" "5"
substrates
[1,] "MCM2;4;|MCM2;5;|MCM2;7;|MCM2;13;|MCM2;27;"
$`cluster 2`
kinase pvalue size
[1,] "CDK2" "0.004316754611606" "15"
substrates
[1,] "HNRNPUL1;716;|HNRNPUL1;718;|MCM4;32;|PAICS;27;|MARCKS;118;|MARCKS;131;|MARCKS;132;|MARCKS;134;|MARCKS;135;|MARCKS;26;|MARCKS;27;|ZC3HC1;394;|ZC3HC1;395;|ELAVL1;202;|MARCKS;133;"
$`cluster 4`
kinase pvalue size
[1,] "ERK2" "0.00124540506797472" "5"
[2,] "ERK1" "0.00267650411136892" "5"
substrates
[1,] "NUP50;221;|CTTN;418;|NUP153;516;|NUP153;522;|ZC3HC1;358;"
[2,] "NUP50;221;|CTTN;418;|NUP153;516;|NUP153;522;|ZC3HC1;358;"
$`cluster 5`
kinase pvalue size
[1,] "CK2A1" "0.000331182736008614" "8"
substrates
[1,] "HMGA2;101;|EIF2S2;67;|CREB1;143;|MYH10;1952;|MYH10;1956;|HMGA2;100;|MYH10;1960;|MDC1;378;"
$`cluster 6`
kinase pvalue size
[1,] "ATM" "0.00244506260354681" "5"
[2,] "CDK1" "0.0109288389890909" "11"
substrates
[1,] "PRKDC;2612;|TP53BP1;1219;|PRKDC;2638;|PRKDC;2647;|PRKDC;2609;"
[2,] "HMGCS1;495;|LMNA;390;|LMNA;392;|NSFL1C;140;|HMGA1;36;|PPP1R12A;473;|LMNB1;23;|DUT;11;|GIGYF2;30;|HMGA1;53;|HIST1H1E;18;"
$`cluster 7`
kinase pvalue size
[1,] "CDK2" "0.0236393247525251" "10"
substrates
[1,] "ADRBK1;670;|CTTN;405;|MCM2;53;|MCM2;40;|ANKRD17;2042;|ANKRD17;2044;|ANKRD17;2045;|NUFIP2;219;|NUFIP2;220;|SF3B1;211;"
$`cluster 8`
kinase pvalue size
[1,] "p70S6K" "8.84512603831859e-06" "7"
[2,] "PKACA" "0.00601962416391702" "5"
substrates
[1,] "NCBP1;22;|RPS6;235;|RPS6;236;|RPS6;240;|RPS6;244;|EIF4B;422;|NCBP1;21;"
[2,] "CTNNB1;552;|RPS6;236;|FLNA;2152;|ARHGEF7;516;|STMN1;16;"
>
> # obtain the optimal clustering object (not run)
> # best$clustObj
>
>
>
>
>
> dev.off()
null device
1
>
 .
.