R: Compares different scores in different regression objects.
forestplotCombineRegrObj
R Documentation
Compares different scores in different regression objects.
Description
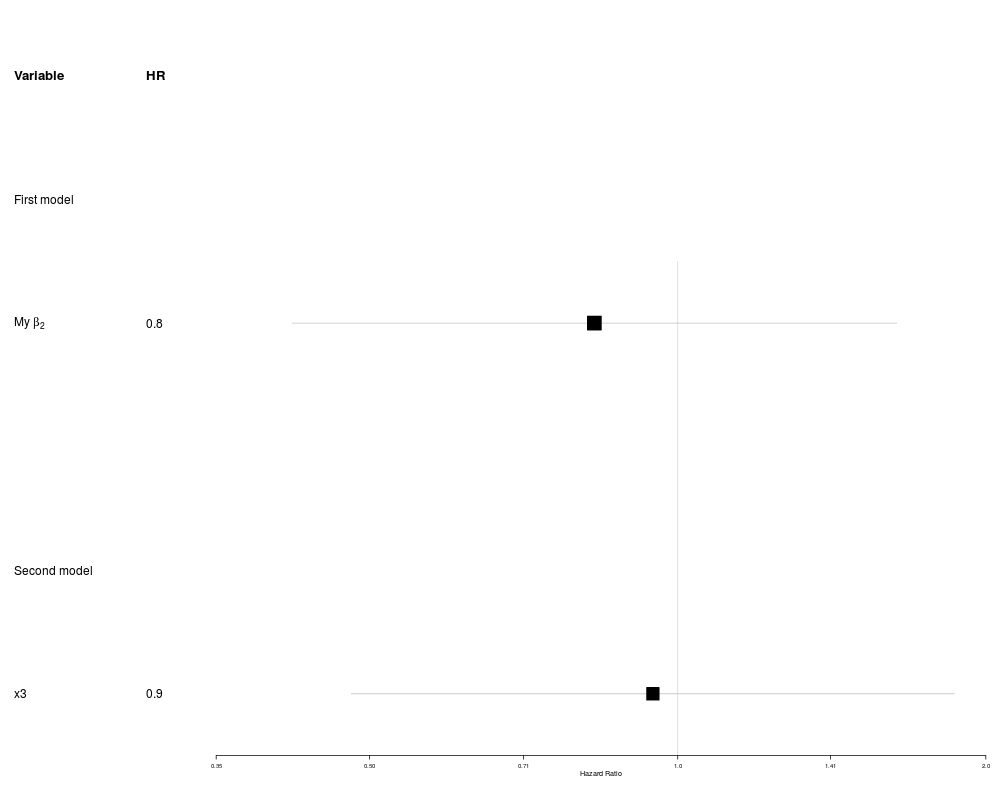
Creates a composite from different regression objects into
one forestplot where you can choose the variables of interest
to get an overview and easier comparison.
A list with all the fits that have variables that are to
be identified through the regular expression
variablesOfInterest.regexp
A regular expression identifying the variables
that are of interest of comparing. For instance it can be "(score|index|measure)"
that finds scores in different models that should be compared.
reference.names
Additional reference names to be added to each model
rowname.fn
A function that takes a rowname and sees if it needs
beautifying. The function has only one parameter the coefficients name and should
return a string or expression.
estimate.txt
The text of the estimate, usually HR for hazard ratio, OR for
odds ratio
exp
Report in exponential form. Default true since the function was built for
use with survival models.
add_first_as_ref
If you want that the first variable should be reference for
that group of variables. The ref is a variable with the estimate 1 or 0 depending
if exp() and the confidence interval 0.
ref_txt
Text instead of estimate number
ref_labels
If add_first_as_ref is TRUE then this vector is used for the model
fits.
digits
Number of digits to use for the estimate output
is.summary
A vector indicating by TRUE/FALSE if
the value is a summary value which means that it will have a different
font-style
xlab
x-axis label
zero
Indicates what is zero effect. For survival/logistic fits the zero is
1 while in most other cases it's 0.
xlog
If TRUE, x-axis tick marks are to follow a logarithmic scale, e.g. for
logistic regressoin (OR), survival estimates (HR), poisson regression etc.
Note: This is an intentional break with the original forestplot
function as I've found that exponentiated ticks/clips/zero effect are more
difficult to for non-statisticians and there are sometimes issues with rounding
the tick marks properly.
 .
.