Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
High Dimensional Discriminant AnalysisDescriptionHDDA is a model-based discriminant analysis method assuming each class of the dataset live in a proper Gaussian subspace which is much smaller than the original one, the hdda.learn function calculates the parameters of each subspace in order to predict the class of new observation of this kind. Usagehdda(data, cls, model='AkjBkQkDk', graph=FALSE, d="Cattell", threshold=0.2, com_dim=NULL, show=TRUE, scaling=FALSE, cv.dim=1:10, cv.threshold=c(.001,.005,.05,1:9*0.1), cv.vfold=10, LOO=FALSE, noise.ctrl=1e-8) Arguments
DetailsSome information on the signification of the model names:
The model “all” will compute all the models, give their BIC and keep the model with the highest BIC value. Instead of writing the model names, they can also be specified using an integer. 1 represents the most general model (“AkjBkQkDk”) while 14 is the most constrained (“ABQD”), the others number/name matching are given below. Note also that several models can be run at once, by using a vector of models (e.g. model = c("AKBKQKD","AKJBQKDK","AJBQD") is equivalent to model = c(8,4,13); to run the 6 first models, use model=1:6). If all the models are to be run, model="all" is faster than model=1:14.
The parameter d, is used to select the intrinsic dimensions of the subclasses. Here are his definictions:
Valuehdda returns an 'hdc' object; it's a list containing:
Author(s)Laurent Berge, Charles Bouveyron and Stephane Girard ReferencesBouveyron, C. Girard, S. and Schmid, C. (2007) “High Dimensional Discriminant Analysis”, Communications in Statistics: Theory and Methods, vol. 36 (14), pp. 2607–2623 Bouveyron, C. Celeux, G. and Girard, S. (2010) “Intrinsic dimension estimation by maximum likelihood in probabilistic PCA”, Technical Report 440372, Universite Paris 1 Pantheon-Sorbonne Berge, L. Bouveyron, C. and Girard, S. (2012) “HDclassif: An R Package for Model-Based Clustering and Discriminant Analysis of High-Dimensional Data”, Journal of Statistical Software, 46(6), 1–29, url: http://www.jstatsoft.org/v46/i06/ See Also
Examples#example 1: data<-simuldata(1000, 1000, 50, K=5) X <- data$X clx <- data$clx Y <- data$Y cly <- data$cly #we get the HDDA parameters: prms1 <- hdda(X, clx) cl1 <- predict(prms1, Y, cly) #the class vector of Y estimated with HDDA: cl1$class #another model is used: prms1 <- hdda(X, clx, model=12) #model=12 is equivalent to model="ABQkD" cl1 <- predict(prms1, Y, cly) #example 2: data(wine) a <- wine[,-1] z <- wine[,1] prms2 <- hdda(a, z, model='all', scaling=TRUE, d="B", graph=TRUE) cl2 <- predict(prms2, a, z) #getting the best dimension #using a common dimension model #we do LOO-CV using cv.vfold=nrow(a) prms3 <- hdda(a, z, model="akjbkqkd", d="CV", cv.vfold=nrow(a), scaling=TRUE, graph=TRUE) cl3 <- predict(prms3, a, z) Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(HDclassif)
Loading required package: MASS
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/HDclassif/hdda.Rd_%03d_medium.png", width=480, height=480)
> ### Name: HDDA
> ### Title: High Dimensional Discriminant Analysis
> ### Aliases: hdda
> ### Keywords: hdda predict classification
>
> ### ** Examples
>
> #example 1:
> data<-simuldata(1000, 1000, 50, K=5)
> X <- data$X
> clx <- data$clx
> Y <- data$Y
> cly <- data$cly
> #we get the HDDA parameters:
> prms1 <- hdda(X, clx)
>
> cl1 <- predict(prms1, Y, cly)
Correct classification rate: 0.944.
Initial class
Predicted class 1 2 3 4 5
1 191 0 0 0 0
2 0 192 0 0 0
3 0 0 207 1 2
4 0 0 2 179 21
5 0 1 10 19 175
> #the class vector of Y estimated with HDDA:
> cl1$class
[1] 3 4 1 5 3 5 1 1 4 1 5 1 5 2 3 1 3 5 1 4 1 3 1 2 2 2 2 4 3 1 4 5 5 3 5 4 3
[38] 4 4 1 4 5 3 2 5 5 2 5 2 2 1 4 4 5 5 4 5 4 5 1 5 3 1 3 4 3 5 4 1 4 5 4 2 4
[75] 3 5 2 4 5 4 1 1 4 5 4 5 2 4 5 4 2 3 2 1 2 1 2 1 1 5 2 2 5 5 3 3 1 5 4 4 2
[112] 2 4 1 4 1 1 4 4 4 2 5 2 2 4 2 1 4 1 3 4 1 3 5 5 3 4 5 4 1 3 4 2 3 5 1 1 2
[149] 2 2 3 5 3 4 4 3 2 4 2 2 5 1 2 2 2 3 1 1 3 1 5 5 2 1 2 3 5 2 2 5 5 2 5 5 1
[186] 3 3 2 5 4 5 1 1 3 5 2 1 4 5 1 2 1 2 1 1 5 3 1 4 5 3 2 2 3 3 1 4 1 5 1 4 1
[223] 2 2 3 5 1 3 4 2 3 5 2 4 3 2 3 4 4 5 1 5 5 1 3 2 5 3 5 4 1 3 4 4 3 1 4 3 3
[260] 3 3 5 3 3 5 4 1 1 2 3 4 5 4 5 1 2 5 5 3 5 2 2 5 4 3 5 3 4 2 1 3 1 1 4 5 1
[297] 3 5 5 4 5 3 3 4 4 4 3 3 4 4 2 2 5 1 5 5 1 1 5 1 2 2 3 4 1 2 2 4 1 5 5 2 2
[334] 5 3 1 2 1 3 5 3 2 5 2 2 1 1 5 4 3 3 3 3 3 4 4 1 2 3 1 4 5 3 5 3 3 2 5 4 4
[371] 5 5 3 4 3 3 5 1 5 1 2 4 4 1 1 3 1 5 4 2 4 1 1 2 1 1 5 2 3 5 2 4 1 4 5 2 4
[408] 2 5 2 1 3 2 4 1 1 3 3 1 1 5 5 2 3 5 2 4 4 3 3 3 5 1 4 3 1 4 4 2 3 4 5 4 2
[445] 3 1 1 3 3 4 2 3 2 4 3 2 4 5 3 2 1 2 5 1 5 4 4 5 1 4 1 5 5 4 5 3 5 3 5 4 4
[482] 2 5 3 2 4 1 3 1 4 3 4 5 4 2 4 4 1 2 3 4 3 1 4 1 4 4 3 2 5 5 5 2 5 2 3 1 3
[519] 2 2 2 4 3 1 1 2 5 3 1 2 3 1 1 2 3 4 5 4 4 5 2 2 4 5 3 1 5 3 4 3 1 2 5 4 2
[556] 2 5 1 4 4 1 2 3 3 3 5 4 4 2 3 5 5 3 5 3 3 3 3 2 5 1 3 2 3 5 5 4 5 3 1 2 5
[593] 3 3 1 2 5 4 4 2 5 2 3 4 2 4 3 1 5 4 3 5 4 4 5 4 3 1 4 4 5 5 5 4 1 1 4 2 1
[630] 5 1 2 3 3 2 2 2 3 4 5 2 2 3 2 5 4 1 4 2 5 4 4 3 3 3 3 5 1 2 2 1 1 4 5 2 3
[667] 1 4 2 5 3 2 3 2 3 3 2 4 1 4 1 2 1 4 5 1 1 2 2 3 5 5 2 2 2 2 4 4 4 3 1 2 3
[704] 3 4 5 1 5 2 2 3 5 4 2 3 5 5 5 4 5 1 5 2 2 1 1 4 1 2 3 4 3 2 2 5 1 5 4 1 4
[741] 3 2 1 4 1 4 5 2 1 5 2 3 4 3 1 3 2 1 1 4 3 1 4 1 3 5 2 3 3 3 4 3 5 3 4 1 3
[778] 5 3 4 1 3 5 5 5 5 4 1 4 3 4 2 4 2 3 3 2 1 3 5 3 4 5 5 3 5 3 1 5 4 3 4 3 3
[815] 4 1 2 2 4 4 5 1 3 2 2 2 4 2 1 5 5 4 3 3 4 3 5 4 3 4 3 4 5 4 3 3 3 1 2 5 1
[852] 3 1 3 4 3 4 4 5 2 1 3 3 4 1 5 1 5 5 2 3 2 2 2 4 4 1 2 5 1 5 5 1 3 3 5 1 5
[889] 3 2 1 1 5 4 2 2 2 2 4 3 4 4 1 1 2 2 5 5 3 1 4 4 5 1 3 1 3 2 1 2 2 4 1 3 3
[926] 1 1 5 5 2 5 3 5 4 5 3 4 1 1 5 2 1 4 2 2 5 2 3 5 5 1 3 5 4 3 2 1 3 5 4 2 1
[963] 5 3 3 1 4 5 3 2 3 4 3 1 4 3 3 1 1 5 3 2 5 2 1 4 4 2 4 1 1 5 5 1 2 2 1 2 1
[1000] 4
Levels: 1 2 3 4 5
>
> #another model is used:
> prms1 <- hdda(X, clx, model=12)
> #model=12 is equivalent to model="ABQkD"
> cl1 <- predict(prms1, Y, cly)
Correct classification rate: 0.764.
Initial class
Predicted class 1 2 3 4 5
1 187 0 18 23 22
2 4 193 11 34 34
3 0 0 182 14 28
4 0 0 6 115 27
5 0 0 2 13 87
>
> #example 2:
> data(wine)
> a <- wine[,-1]
> z <- wine[,1]
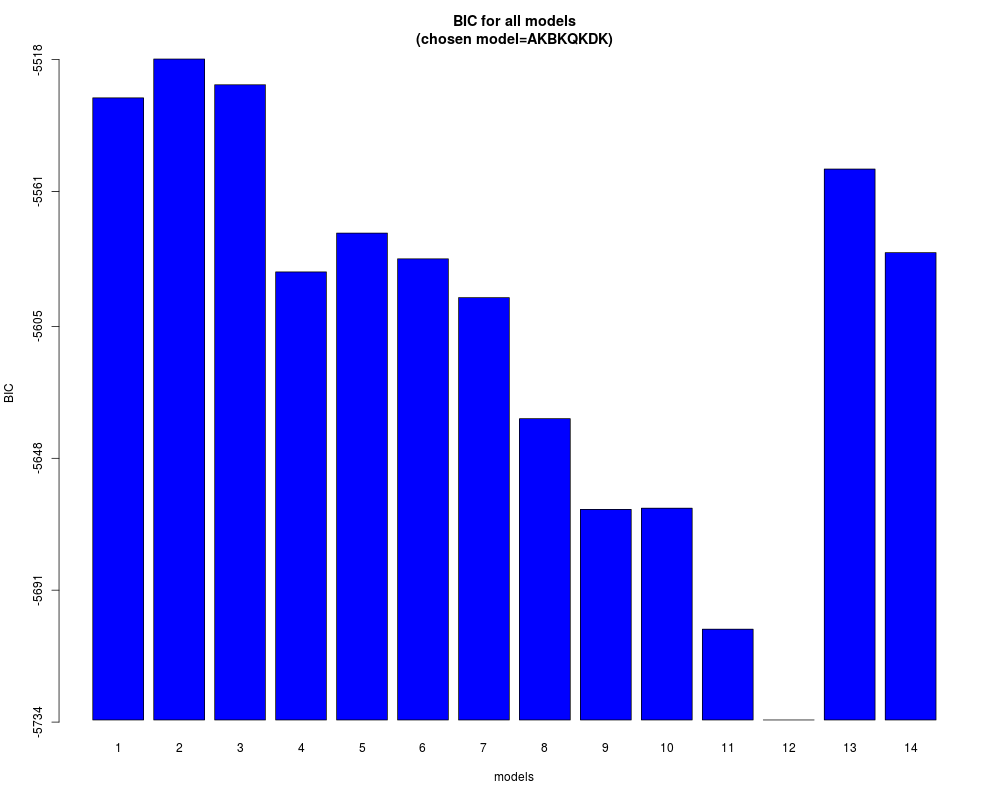
> prms2 <- hdda(a, z, model='all', scaling=TRUE, d="B", graph=TRUE)
# : Model BIC
1 : AKJBKQKDK -5530.507
2 : AKBKQKDK -5517.848
3 : ABKQKDK -5526.241
4 : AKJBQKDK -5587.252
5 : AKBQKDK -5574.594
6 : ABQKDK -5582.986
7 : AKJBKQKD -5595.633
8 : AKBKQKD -5635.083
9 : ABKQKD -5664.665
10 : AKJBQKD -5664.273
11 : AKBQKD -5703.723
12 : ABQKD -5733.304
13 : AJBQD -5553.715
14 : ABQD -5580.956
SELECTED: Model AKBKQKDK, BIC=-5517.848.
> cl2 <- predict(prms2, a, z)
Correct classification rate: 1.
Initial class
Predicted class 1 2 3
1 59 0 0
2 0 71 0
3 0 0 48
>
> #getting the best dimension
> #using a common dimension model
> #we do LOO-CV using cv.vfold=nrow(a)
> prms3 <- hdda(a, z, model="akjbkqkd", d="CV", cv.vfold=nrow(a), scaling=TRUE, graph=TRUE)
Model dim CV
AKJBKQKD 1 95.50562
AKJBKQKD 2 98.8764
AKJBKQKD 3 97.19101
AKJBKQKD 4 98.8764
AKJBKQKD 5 100
AKJBKQKD 6 98.8764
AKJBKQKD 7 98.8764
AKJBKQKD 8 98.31461
AKJBKQKD 9 99.4382
AKJBKQKD 10 98.8764
Best dimension with respect to the CV results: 5.
>
> cl3 <- predict(prms3, a, z)
Correct classification rate: 1.
Initial class
Predicted class 1 2 3
1 59 0 0
2 0 71 0
3 0 0 48
>
>
>
>
>
>
> dev.off()
null device
1
>
|