Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
Estimation of Number of Clusters in DataDescription
UsageINCAnumclu(d, K, method = "pam", pert, L= NULL, noise=NULL) Arguments
ValueReturns an object of class Author(s)Itziar Irigoien itziar.irigoien@ehu.es; Konputazio Zientziak eta Adimen Artifiziala, Euskal Herriko Unibertsitatea (UPV-EHU), Donostia, Spain. Conchita Arenas carenas@ub.edu; Departament d'Estadistica, Universitat de Barcelona, Barcelona, Spain. ReferencesIrigoien, I. and Arenas, C. (2008). INCA: New statistic for estimating the number of clusters and identifying atypical units. Statistics in Medicine, 27(15), 2948–2973. Arenas, C. and Cuadras, C.M. (2002). Some recent statistical methods based on distances. Contributions to Science, 2, 183–191. See Also
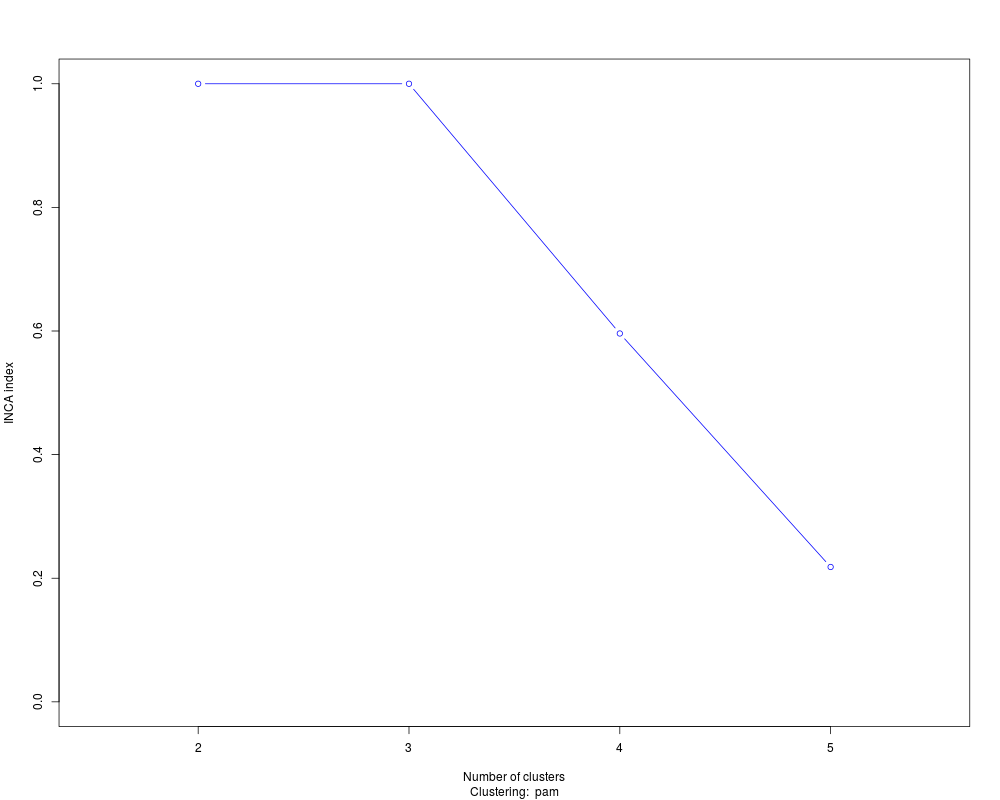
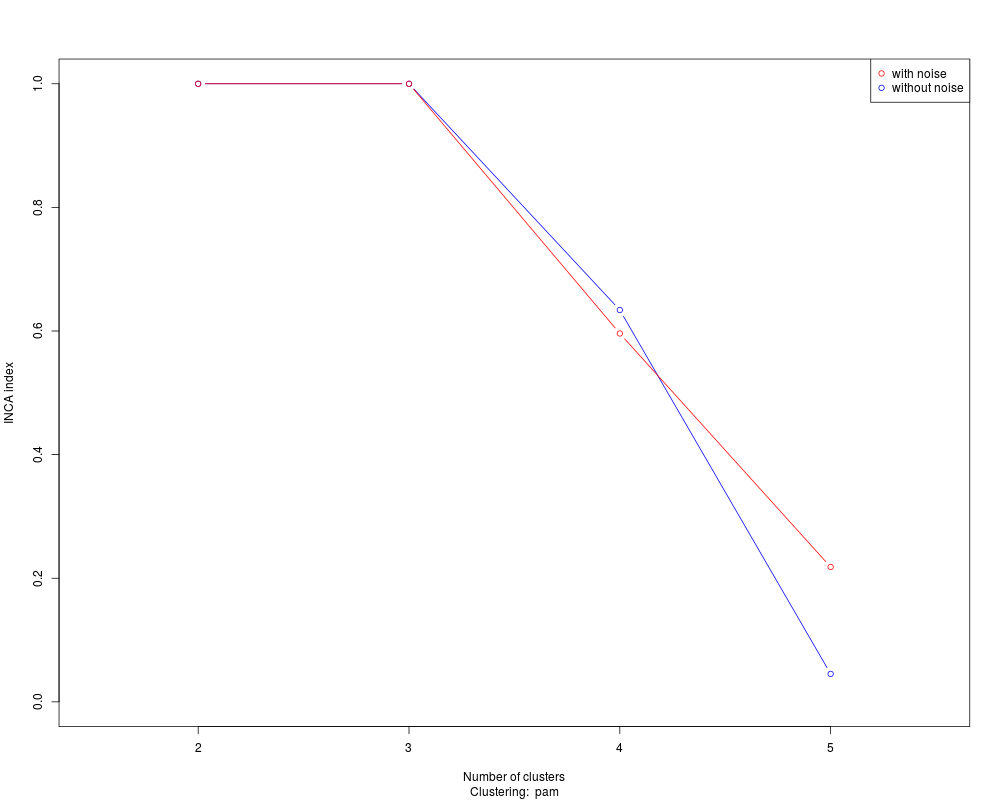
Examples#------- Example 1 -------------------------------------- #generate 3 clusters, each of them with 20 objects in dimension 5. mu1 <- sample(1:10, 5, replace=TRUE) x1 <- matrix(rnorm(20*5, mean = mu1, sd = 1),ncol=5, byrow=TRUE) mu2 <- sample(1:10, 5, replace=TRUE) x2 <- matrix(rnorm(20*5, mean = mu2, sd = 1),ncol=5, byrow=TRUE) mu3 <- sample(1:10, 5, replace=TRUE) x3 <- matrix(rnorm(20*5, mean = mu3, sd = 1),ncol=5, byrow=TRUE) x <- rbind(x1,x2,x3) # calculte euclidean distance between them d <- dist(x) # calculate the INCA index associated to partitions with k=2, ..., k=5 clusters. INCAnumclu(d, K=5) out <- INCAnumclu(d, K=5) plot(out) #------- Example 1 cont. -------------------------------- # With hypothetical noise elements noiseunits <- rep(FALSE, 60) noiseunits[sample(1:60, 20)] <- TRUE out <- INCAnumclu(d, K=5, L="custom", noise=noiseunits) plot(out) Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(ICGE)
Loading required package: MASS
Loading required package: cluster
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/ICGE/INCAnumclu.Rd_%03d_medium.png", width=480, height=480)
> ### Name: INCAnumclu
> ### Title: Estimation of Number of Clusters in Data
> ### Aliases: INCAnumclu plot.incanc print.incanc
> ### Keywords: multivariate cluster
>
> ### ** Examples
>
> #------- Example 1 --------------------------------------
> #generate 3 clusters, each of them with 20 objects in dimension 5.
> mu1 <- sample(1:10, 5, replace=TRUE)
> x1 <- matrix(rnorm(20*5, mean = mu1, sd = 1),ncol=5, byrow=TRUE)
> mu2 <- sample(1:10, 5, replace=TRUE)
> x2 <- matrix(rnorm(20*5, mean = mu2, sd = 1),ncol=5, byrow=TRUE)
> mu3 <- sample(1:10, 5, replace=TRUE)
> x3 <- matrix(rnorm(20*5, mean = mu3, sd = 1),ncol=5, byrow=TRUE)
> x <- rbind(x1,x2,x3)
>
> # calculte euclidean distance between them
> d <- dist(x)
>
> # calculate the INCA index associated to partitions with k=2, ..., k=5 clusters.
> INCAnumclu(d, K=5)
---INCA index to estimate the number of clusters---
Clustering method: pam
k= 2 1
k= 3 1
k= 4 0.49
k= 5 0.1
> out <- INCAnumclu(d, K=5)
> plot(out)
>
> #------- Example 1 cont. --------------------------------
> # With hypothetical noise elements
> noiseunits <- rep(FALSE, 60)
> noiseunits[sample(1:60, 20)] <- TRUE
> out <- INCAnumclu(d, K=5, L="custom", noise=noiseunits)
> plot(out)
>
>
>
>
>
> dev.off()
null device
1
>
|