R: Model evaluation measures for Binary classification models
staticPerfMeasures
R Documentation
Model evaluation measures for Binary classification models
Description
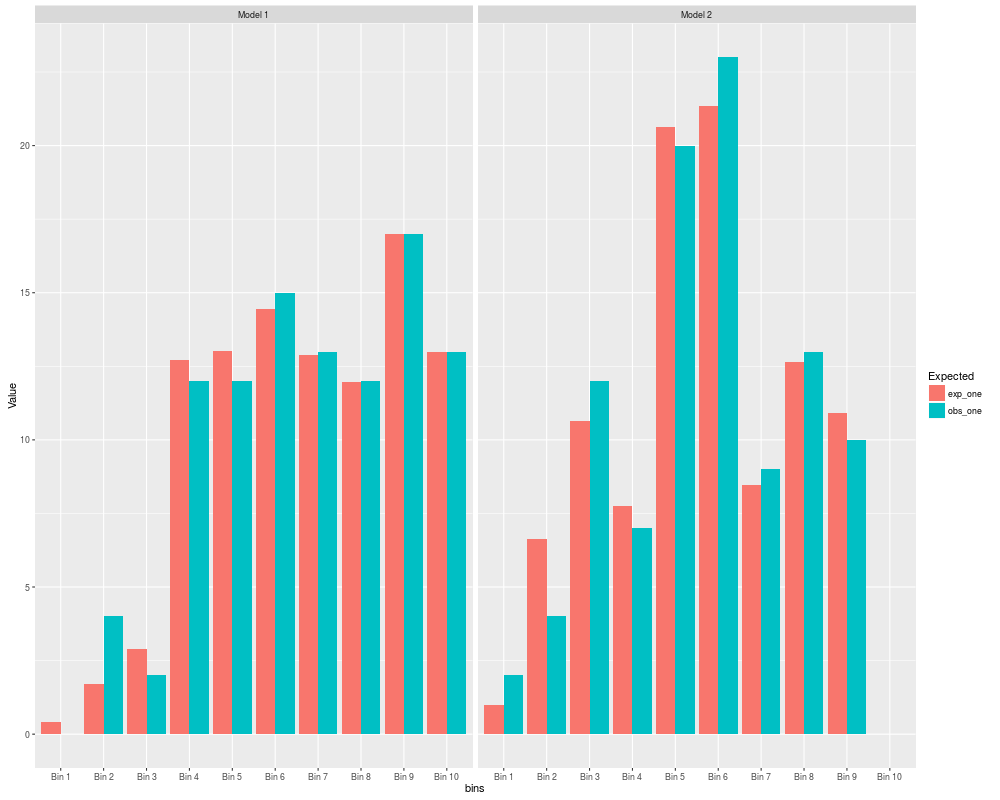
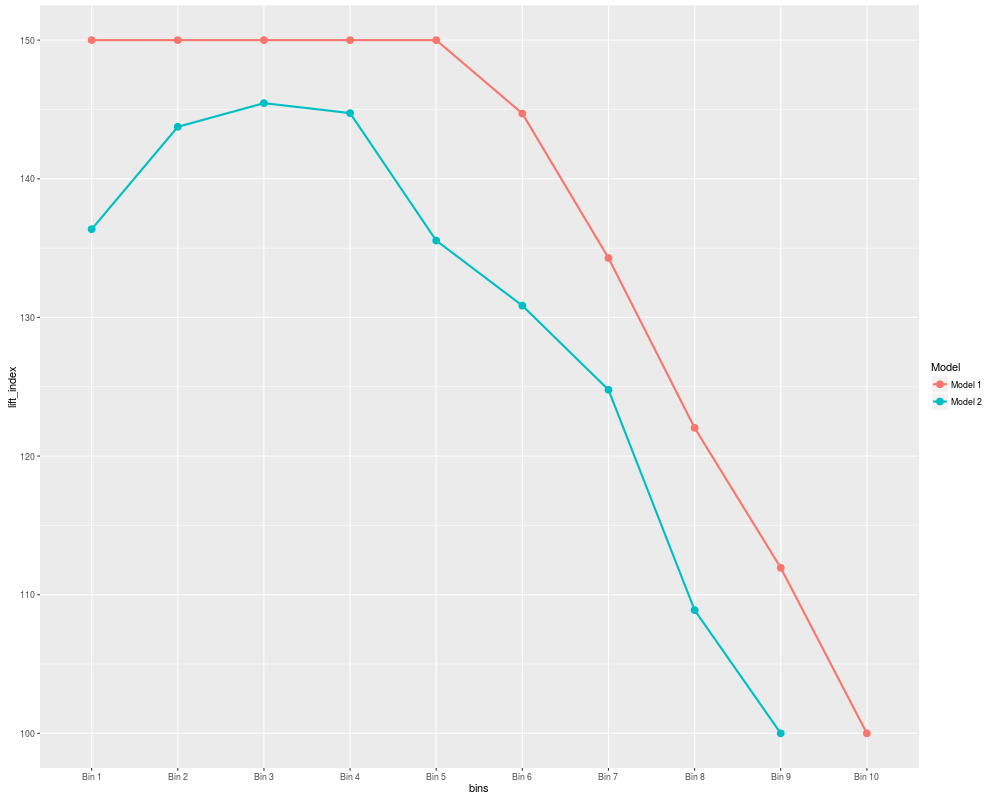
Generates & plots the following performance evaluation & validation measures for Binary Classification Models - Hosmer Lemeshow goodness of fit tests,
Calibration plots, Lift index & gain charts & concordance-discordance measures
A list of one (or more) dataframes for each model whose performance is to be evaluated. Each dataframe should comprise of 2 columns with the first column indicating the class labels (0 or 1)
and the second column providing the raw predicted probabilities
g
The number of groups for binning. The predicted probabilities are binned as follows
For Hosmer-Lemshow (HL) test: Predicted probabilities binned as per g unique quantiles i.e. cut_points = unique(quantile(predicted_prob,seq(0,1,1/g)))
For Lift-Index & Gain charts: Same as HL test, however if g > unique(predicted_probability), the predicted probabilities
are used as such without binning
For calibration plots, g equal sized intervals are created (of width 1/g each)
perf_measures
Select the required performance evaluation and validation measure/s, from the following
options - c('hosmer','calibration','lift','concord'). Default option is All
sample_size_concord
For computing concordance-discordance measures (and c-statistic) a random sample
is drawn from each dataset (if nrow(dataset) > 5000). Default sample size of 5000 can be adjusted by changing the value of this
argument
Value
A nested list with 2 components - a list of dataframes and a list of plots - containing
the outcomes of the different performance evaluations carried out.
 .
.