Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
Fits the regularization paths for the kernel expectile regression.DescriptionFits a regularization path for the kernel expectile regression at a sequence of regularization parameters lambda. Usage
KERE(x, y, kern, lambda = NULL, eps = 1e-08, maxit = 1e4,
omega = 0.5, gamma = 1e-06, option = c("fast", "normal"))
Arguments
DetailsNote that the objective function in Loss(y- α_0 - K * α )) + λ * α^T * K * α, where the α_0 is the intercept, α is the solution vector, and K is the kernel matrix with K_{ij}=K(x_i,x_j). Users can specify the kernel function to use, options include Radial Basis kernel, Polynomial kernel, Linear kernel, Hyperbolic tangent kernel, Laplacian kernel, Bessel kernel, ANOVA RBF kernel, the Spline kernel. Users can also tweak the penalty by choosing different lambda. For computing speed reason, if models are not converging or running slow, consider increasing ValueAn object with S3 class
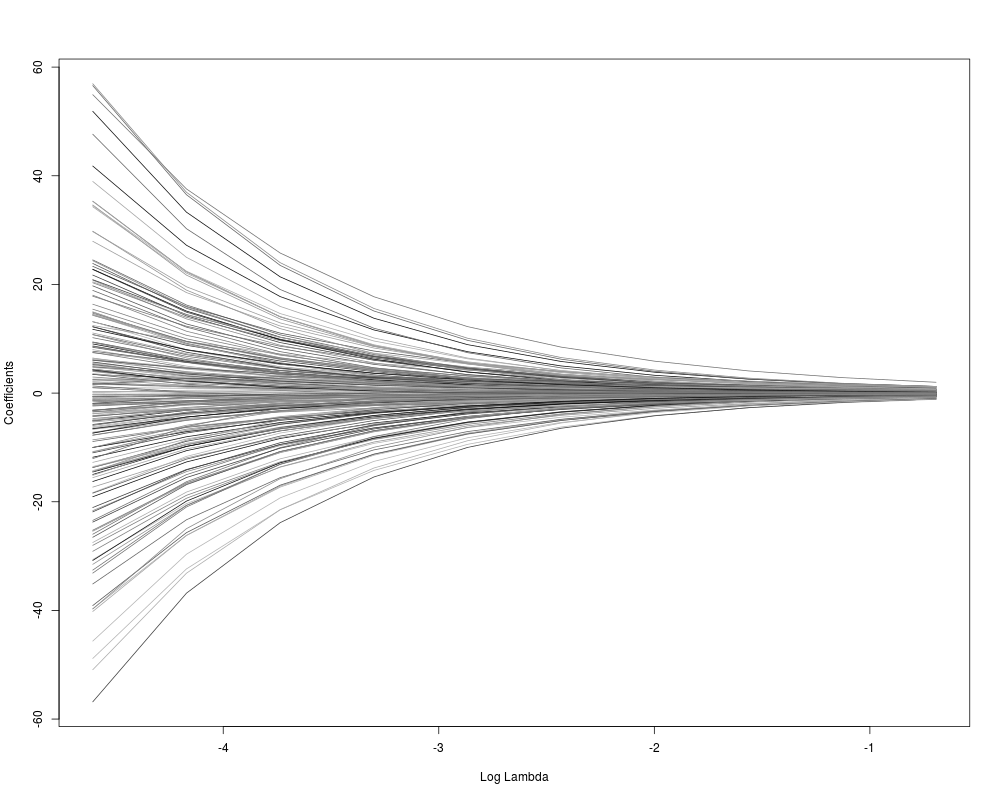
Author(s)Yi Yang, Teng Zhang and Hui Zou ReferencesY. Yang, T. Zhang, and H. Zou. "Flexible Expectile Regression in Reproducing Kernel Hilbert Space." ArXiv e-prints: stat.ME/1508.05987, August 2015. Examples# create data N <- 200 X1 <- runif(N) X2 <- 2*runif(N) X3 <- 3*runif(N) SNR <- 10 # signal-to-noise ratio Y <- X1**1.5 + 2 * (X2**.5) + X1*X3 sigma <- sqrt(var(Y)/SNR) Y <- Y + X2*rnorm(N,0,sigma) X <- cbind(X1,X2,X3) # set gaussian kernel kern <- rbfdot(sigma=0.1) # define lambda sequence lambda <- exp(seq(log(0.5),log(0.01),len=10)) # run KERE m1 <- KERE(x=X, y=Y, kern=kern, lambda = lambda, omega = 0.5) # plot the solution paths plot(m1) Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(KERE)
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/KERE/KERE.Rd_%03d_medium.png", width=480, height=480)
> ### Name: KERE
> ### Title: Fits the regularization paths for the kernel expectile
> ### regression.
> ### Aliases: KERE
> ### Keywords: models regression
>
> ### ** Examples
>
> # create data
> N <- 200
> X1 <- runif(N)
> X2 <- 2*runif(N)
> X3 <- 3*runif(N)
> SNR <- 10 # signal-to-noise ratio
> Y <- X1**1.5 + 2 * (X2**.5) + X1*X3
> sigma <- sqrt(var(Y)/SNR)
> Y <- Y + X2*rnorm(N,0,sigma)
> X <- cbind(X1,X2,X3)
>
> # set gaussian kernel
> kern <- rbfdot(sigma=0.1)
>
> # define lambda sequence
> lambda <- exp(seq(log(0.5),log(0.01),len=10))
>
> # run KERE
> m1 <- KERE(x=X, y=Y, kern=kern, lambda = lambda, omega = 0.5)
>
> # plot the solution paths
> plot(m1)
>
>
>
>
>
>
> dev.off()
null device
1
>
|