Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
KFAS: Functions for Exponential Family State Space ModelsDescriptionPackage KFAS contains functions for Kalman filtering, smoothing and simulation of linear state space models with exact diffuse initialization. DetailsNote, this help page might be more readable in pdf format due to the mathematical formulas containing subscripts. The linear Gaussian state space model is given by y[t] = Z[t]α[t] + ε[t], (observation equation) α[t+1] = T[t]α[t] + R[t]η[t], (transition equation) where ε[t] ~ N(0, H[t]), η[t] ~ N(0, Q[t]) and α[1] ~ N(a[1], P[1]) independently of each other. All system and covariance matrices Covariance matrices H and Q has to be positive semidefinite (although this is not checked). Model components in
In case of any of the series in model is defined as non-Gaussian, the observation equation is of form ∏[i]^p p(y[t, i]|θ[t]), with θ[t, i] = Z[i, t]α[t] being one of the following:
For exponential family models u[t] = 1 as a default. For completely Gaussian models, parameter is omitted. Note that series can have different distributions in case of multivariate models. For the unknown elements of initial state vector a[1], KFAS uses exact diffuse initialization by Koopman and Durbin (2000, 2012, 2003), where the unknown initial states are set to have a zero mean and infinite variance, so P[1] = P[*, 1] + κP[inf, 1], with κ going to infinity and P[inf, 1] being diagonal matrix with ones on diagonal elements corresponding to unknown initial states. This method is basically a equivalent of setting uninformative priors for the initial states in a Bayesian framework. Diffuse phase is continued until rank of P[inf, t] becomes
zero. Rank of P[inf, t] decreases by 1, if
F[inf, t]>ξ[t]>0, where ξ[t] is by default
To lessen the notation and storage space, KFAS uses letters P, F and K for non-diffuse part of the corresponding matrices, omitting the asterisk in diffuse phase. All functions of KFAS use the univariate approach (also known as sequential
processing, see Anderson and Moore (1979)) which is from Koopman and Durbin
(2000, 2012). In univariate approach the observations are introduced one
element at the time. Therefore the prediction error variance matrices F and
Finf do not need to be non-singular, as there is no matrix inversions in
univariate approach algorithm. This provides possibly more
faster filtering and smoothing than normal multivariate Kalman filter
algorithm, and simplifies the formulas for diffuse filtering and smoothing.
If covariance matrix H is not diagonal, it is possible to transform the model by either using
LDL decomposition on H, or augmenting the state vector with ε
disturbances (this is done automatically in KFAS if needed).
See ReferencesKoopman, S.J. and Durbin J. (2000). Fast filtering and smoothing for non-stationary time series models, Journal of American Statistical Assosiation, 92, 1630-38. Koopman, S.J. and Durbin J. (2012). Time Series Analysis by State Space Methods. Second edition. Oxford: Oxford University Press. Koopman, S.J. and Durbin J. (2003). Filtering and smoothing of state vector for diffuse state space models, Journal of Time Series Analysis, Vol. 24, No. 1. Shumway, Robert H. and Stoffer, David S. (2006). Time Series Analysis and
Its Applications: With R examples. See Alsoexamples in Examples
# Example of local level model for Nile series
# See Durbin and Koopman (2012)
model_Nile <- SSModel(Nile ~
SSMtrend(1, Q = list(matrix(NA))), H = matrix(NA))
model_Nile
model_Nile <- fitSSM(model_Nile, c(log(var(Nile)), log(var(Nile))),
method = "BFGS")$model
# Filtering and state smoothing
out_Nile <- KFS(model_Nile, filtering = "state", smoothing = "state")
out_Nile
# Confidence and prediction intervals for the expected value and the observations.
# Note that predict uses original model object, not the output from KFS.
conf_Nile <- predict(model_Nile, interval = "confidence", level = 0.9)
pred_Nile <- predict(model_Nile, interval = "prediction", level = 0.9)
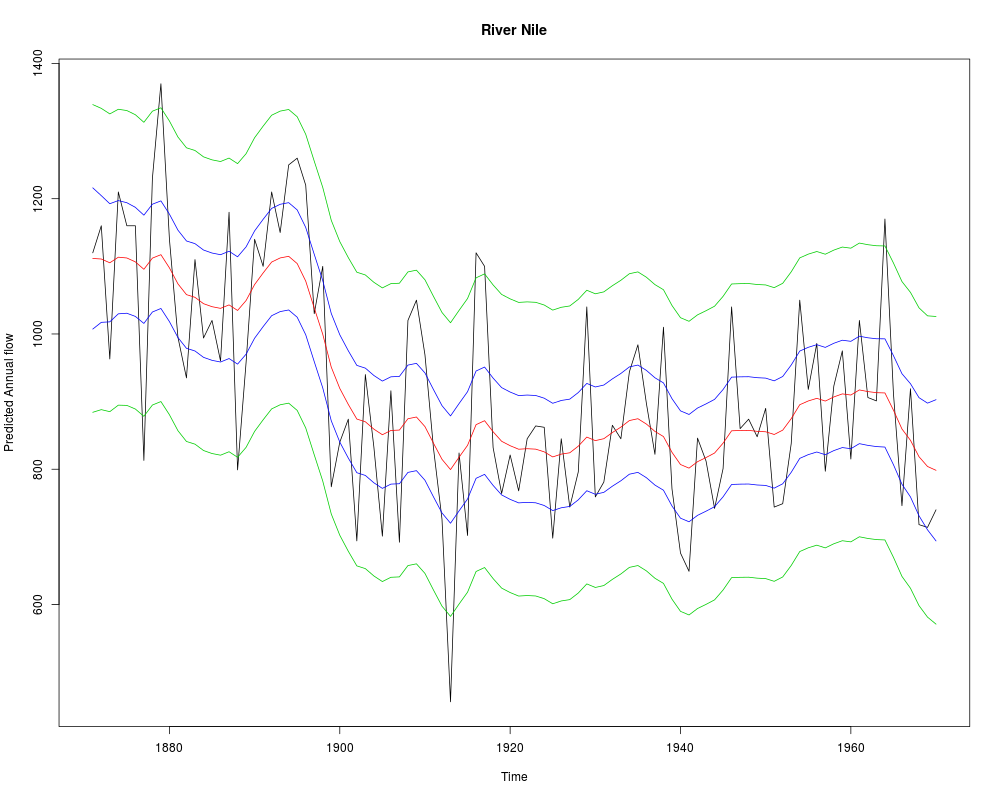
ts.plot(cbind(Nile, pred_Nile, conf_Nile[, -1]), col = c(1:2, 3, 3, 4, 4),
ylab = "Predicted Annual flow", main = "River Nile")
# Missing observations, using the same parameter estimates
NileNA <- Nile
NileNA[c(21:40, 61:80)] <- NA
model_NileNA <- SSModel(NileNA ~ SSMtrend(1, Q = list(model_Nile$Q)),
H = model_Nile$H)
out_NileNA <- KFS(model_NileNA, "mean", "mean")
# Filtered and smoothed states
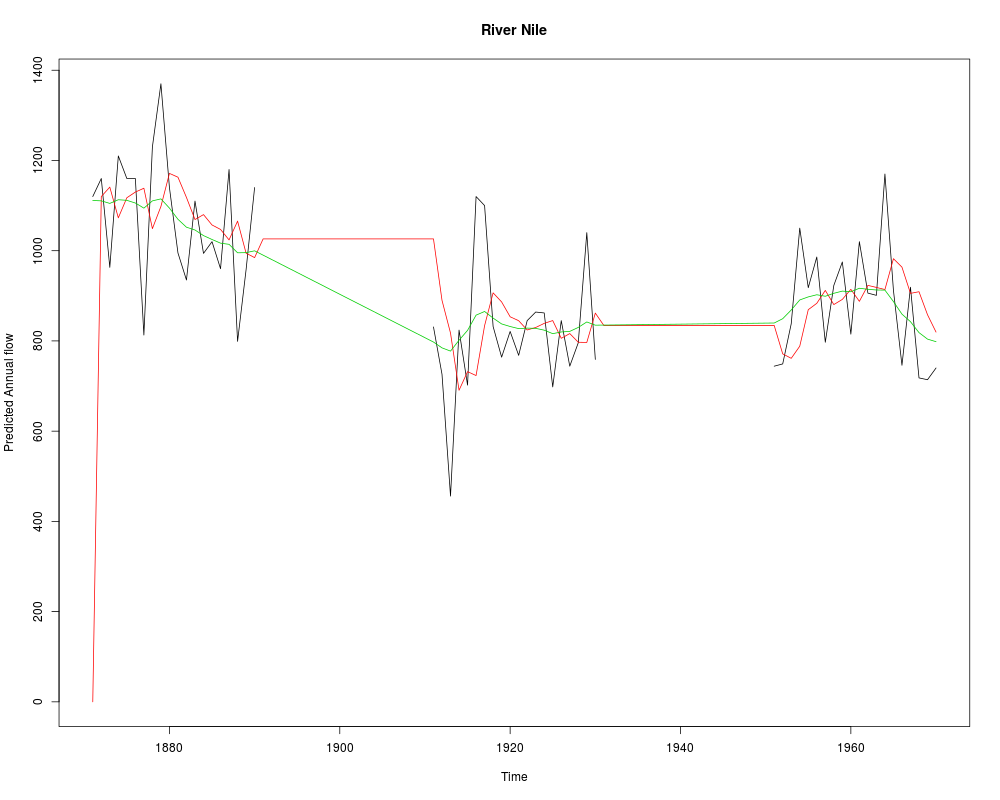
ts.plot(NileNA, fitted(out_NileNA, filtered = TRUE), fitted(out_NileNA),
col = 1:3, ylab = "Predicted Annual flow",
main = "River Nile")
# Example of multivariate local level model with only one state
# Two series of average global temperature deviations for years 1880-1987
# See Shumway and Stoffer (2006), p. 327 for details
data("GlobalTemp")
model_temp <- SSModel(GlobalTemp ~ SSMtrend(1, Q = NA, type = "common"),
H = matrix(NA, 2, 2))
# Estimating the variance parameters
inits <- chol(cov(GlobalTemp))[c(1, 4, 3)]
inits[1:2] <- log(inits[1:2])
fit_temp <- fitSSM(model_temp, c(0.5*log(.1), inits), method = "BFGS")
out_temp <- KFS(fit_temp$model)
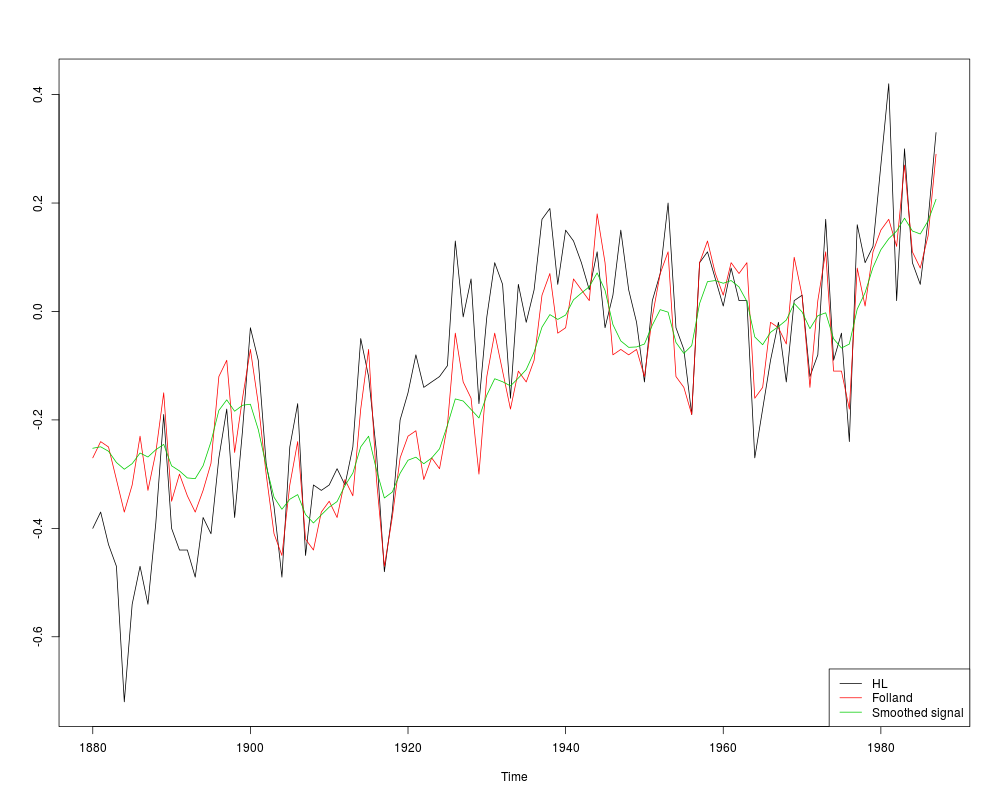
ts.plot(cbind(model_temp$y, coef(out_temp)), col = 1:3)
legend("bottomright",
legend = c(colnames(GlobalTemp), "Smoothed signal"), col = 1:3, lty = 1)
## Not run:
# Seatbelts data
# See Durbin and Koopman (2012)
model_drivers <- SSModel(log(drivers) ~ SSMtrend(1, Q = list(NA))+
SSMseasonal(period = 12, sea.type = "trigonometric", Q = NA) +
log(PetrolPrice) + law, data = Seatbelts, H = NA)
# As trigonometric seasonal contains several disturbances which are all
# identically distributed, default behaviour of fitSSM is not enough,
# as we have constrained Q. We can either provide our own
# model updating function with fitSSM, or just use optim directly:
# option 1:
ownupdatefn <- function(pars, model){
model$H[] <- exp(pars[1])
diag(model$Q[, , 1]) <- exp(c(pars[2], rep(pars[3], 11)))
model #for optim, replace this with -logLik(model) and call optim directly
}
fit_drivers <- fitSSM(model_drivers,
log(c(var(log(Seatbelts[, "drivers"])), 0.001, 0.0001)),
ownupdatefn, method = "BFGS")
out_drivers <- KFS(fit_drivers$model, smoothing = c("state", "mean"))
out_drivers
ts.plot(out_drivers$model$y, fitted(out_drivers), lty = 1:2, col = 1:2,
main = "Observations and smoothed signal with and without seasonal component")
lines(signal(out_drivers, states = c("regression", "trend"))$signal,
col = 4, lty = 1)
legend("bottomleft", col = c(1, 2, 4), lty = c(1, 2, 1),
legend = c("Observations", "Smoothed signal", "Smoothed level"))
# Multivariate model with constant seasonal pattern,
# using the the seat belt law dummy only for the front seat passangers,
# and restricting the rank of the level component by using custom component
model_drivers2 <- SSModel(log(cbind(front, rear)) ~ -1 +
log(PetrolPrice) + log(kms) +
SSMregression(~law, data = Seatbelts, index = 1) +
SSMcustom(Z = diag(2), T = diag(2), R = matrix(1, 2, 1),
Q = matrix(1), P1inf = diag(2)) +
SSMseasonal(period = 12, sea.type = "trigonometric"),
data = Seatbelts, H = matrix(NA, 2, 2))
# An alternative way for defining the rank deficient trend component:
# model_drivers2 <- SSModel(log(cbind(front, rear)) ~ -1 +
# log(PetrolPrice) + log(kms) +
# SSMregression(~law, data = Seatbelts, index = 1) +
# SSMtrend(degree = 1, Q = list(matrix(0, 2, 2))) +
# SSMseasonal(period = 12, sea.type = "trigonometric"),
# data = Seatbelts, H = matrix(NA, 2, 2))
#
# Modify model manually:
# model_drivers2$Q <- array(1, c(1, 1, 1))
# model_drivers2$R <- model_drivers2$R[, -2, , drop = FALSE]
# attr(model_drivers2, "k") <- 1L
# attr(model_drivers2, "eta_types") <- attr(model_drivers2, "eta_types")[1]
likfn <- function(pars, model, estimate = TRUE){
diag(model$H[, , 1]) <- exp(0.5 * pars[1:2])
model$H[1, 2, 1] <- model$H[2, 1, 1] <-
tanh(pars[3]) * prod(sqrt(exp(0.5 * pars[1:2])))
model$R[28:29] <- exp(pars[4:5])
if(estimate) return(-logLik(model))
model
}
fit_drivers2 <- optim(f = likfn, p = c(-8, -8, 1, -1, -3), method = "BFGS",
model = model_drivers2)
model_drivers2 <- likfn(fit_drivers2$p, model_drivers2, estimate = FALSE)
model_drivers2$R[28:29, , 1]%*%t(model_drivers2$R[28:29, , 1])
model_drivers2$H
out_drivers2 <- KFS(model_drivers2)
out_drivers2
ts.plot(signal(out_drivers2, states = c("custom", "regression"))$signal,
model_drivers2$y, col = 1:4)
# For confidence or prediction intervals, use predict on the original model
pred <- predict(model_drivers2,
states = c("custom", "regression"), interval = "prediction")
# Note that even though the intervals were computed without seasonal pattern,
# PetrolPrice induces seasonal pattern to predictions
ts.plot(pred$front, pred$rear, model_drivers2$y,
col = c(1, 2, 2, 3, 4, 4, 5, 6), lty = c(1, 2, 2, 1, 2, 2, 1, 1))
## End(Not run)
## Simulate ARMA(2, 2) process
set.seed(1)
y <- arima.sim(n = 1000, list(ar = c(0.8897, -0.4858), ma = c(-0.2279, 0.2488)),
innov = rnorm(1000) * sqrt(0.5))
model_arima <- SSModel(y ~ SSMarima(ar = c(0, 0), ma = c(0, 0), Q = 1), H = 0)
likfn <- function(pars, model, estimate = TRUE){
tmp <- try(SSMarima(artransform(pars[1:2]), artransform(pars[3:4]),
Q = exp(pars[5])), silent = TRUE)
if(!inherits(tmp, "try-error")){
model["T", "arima"] <- tmp$T
model["R", "arima"] <- tmp$R
model["P1", "arima"] <- tmp$P1
model["Q", "arima"] <- tmp$Q
if(estimate){
-logLik(model)
} else model
} else {
if(estimate){
1e100
} else model
}
}
fit_arima <- optim(par = c(rep(0, 4), log(1)), fn = likfn, method = "BFGS",
model = model_arima)
model_arima <- likfn(fit_arima$par, model_arima, FALSE)
# AR coefficients:
model_arima$T[2:3, 2, 1]
# MA coefficients:
model_arima$R[3:4]
# sigma2:
model_arima$Q[1]
# intercept
KFS(model_arima)
# same with arima:
arima(y, c(2, 0, 2))
# small differences because the intercept is handled differently in arima
## Not run:
# Poisson model
# See Durbin and Koopman (2012)
model_van <- SSModel(VanKilled ~ law + SSMtrend(1, Q = list(matrix(NA)))+
SSMseasonal(period = 12, sea.type = "dummy", Q = NA),
data = Seatbelts, distribution = "poisson")
# Estimate variance parameters
fit_van <- fitSSM(model_van, c(-4, -7), method = "BFGS")
model_van <- fit_van$model
# use approximating model, gives posterior modes
out_nosim <- KFS(model_van, nsim = 0)
# State smoothing via importance sampling
out_sim <- KFS(model_van, nsim = 1000)
out_nosim
out_sim
## End(Not run)
##########################################################
### Examples of generalized linear modelling with KFAS ###
##########################################################
# Same example as in ?glm
counts <- c(18, 17, 15, 20, 10, 20, 25, 13, 12)
outcome <- gl(3, 1, 9)
treatment <- gl(3, 3)
glm_D93 <- glm(counts ~ outcome + treatment, family = poisson())
model_D93 <- SSModel(counts ~ outcome + treatment,
distribution = "poisson")
out_D93 <- KFS(model_D93)
coef(out_D93, last = TRUE)
coef(glm_D93)
summary(glm_D93)$cov.s
out_D93$V[, , 1]
# approximating model as in GLM
out_D93_nosim <- KFS(model_D93, smoothing = c("state", "signal", "mean"))
# with importance sampling. Number of simulations is too small here,
# with large enough nsim the importance sampling actually gives
# very similar results as the approximating model in this case
set.seed(1)
out_D93_sim <- KFS(model_D93,
smoothing = c("state", "signal", "mean"), nsim = 1000)
## linear predictor
# GLM
glm_D93$linear.predictor
# approximate model, this is the posterior mode of p(theta|y)
c(out_D93_nosim$thetahat)
# importance sampling on theta, gives E(theta|y)
c(out_D93_sim$thetahat)
## predictions on response scale
# GLM
fitted(glm_D93)
# approximate model with backtransform, equals GLM
fitted(out_D93_nosim)
# importance sampling on exp(theta)
fitted(out_D93_sim)
# prediction variances on link scale
# GLM
as.numeric(predict(glm_D93, type = "link", se.fit = TRUE)$se.fit^2)
# approx, equals to GLM results
c(out_D93_nosim$V_theta)
# importance sampling on theta
c(out_D93_sim$V_theta)
# prediction variances on response scale
# GLM
as.numeric(predict(glm_D93, type = "response", se.fit = TRUE)$se.fit^2)
# approx, equals to GLM results
c(out_D93_nosim$V_mu)
# importance sampling on theta
c(out_D93_sim$V_mu)
# A Gamma example modified from ?glm
# Now with log-link, and identical intercept terms
clotting <- data.frame(
u = c(5,10,15,20,30,40,60,80,100),
lot1 = c(118,58,42,35,27,25,21,19,18),
lot2 = c(69,35,26,21,18,16,13,12,12))
model_gamma <- SSModel(cbind(lot1, lot2) ~ -1 + log(u) +
SSMregression(~ 1, type = "common", remove.intercept = FALSE),
data = clotting, distribution = "gamma")
update_shapes <- function(pars, model) {
model$u[, 1] <- pars[1]
model$u[, 2] <- pars[2]
model
}
fit_gamma <- fitSSM(model_gamma, inits = c(1, 1), updatefn = update_shapes,
method = "L-BFGS-B", lower = 0, upper = 100)
logLik(fit_gamma$model)
KFS(fit_gamma$model)
fit_gamma$model["u", times = 1]
## Not run:
####################################
### Linear mixed model with KFAS ###
####################################
# example from ?lmer of lme4 pacakge
data("sleepstudy", package = "lme4")
model_lmm <- SSModel(Reaction ~ Days +
SSMregression(~ Days, Q = array(0, c(2, 2, 180)),
P1 = matrix(NA, 2, 2), remove.intercept = FALSE), sleepstudy, H = NA)
# The first 10 time points the third and fouth state
# defined with SSMregression correspond to the first subject, and next 10 time points
# are related to second subject and so on.
# need to use ordinary $ assignment as [ assignment operator for SSModel
# object guards against dimension altering
model_lmm$T <- array(model_lmm["T"], c(4, 4, 180))
attr(model_lmm, "tv")[3] <- 1L #needs to be integer type!
# "cut the connection" between the subjects
times <- seq(10, 180, by = 10)
model_lmm["T",states = 3:4, times = times] <- 0
# for the first subject the variance of the random effect is defined via P1
# for others, we use Q
model_lmm["Q", times = times] <- NA
update_lmm <- function(pars = init, model){
P1 <- diag(exp(pars[1:2]))
P1[1, 2] <- pars[3]
model["P1", states = 3:4] <- model["Q", times = times] <-
crossprod(P1)
model["H"] <- exp(pars[4])
model
}
inits <- c(0, 0, 0, 3)
fit_lmm <- fitSSM(model_lmm, inits, update_lmm, method = "BFGS")
out_lmm <- KFS(fit_lmm$model)
# unconditional covariance matrix of random effects
fit_lmm$model["P1", states = 3:4]
# conditional covariance matrix of random effects
# same for each subject and time point due to model structure
# these differ from the ones obtained from lmer as these are not conditioned
# on the fixed effects
out_lmm$V[3:4,3:4,1]
## End(Not run)
## Not run:
# Example of Cubic spline smoothing
# See Durbin and Koopman (2012)
require("MASS")
data("mcycle")
model <- SSModel(accel ~ -1 +
SSMcustom(Z = matrix(c(1, 0), 1, 2),
T = array(diag(2), c(2, 2, nrow(mcycle))),
Q = array(0, c(2, 2, nrow(mcycle))),
P1inf = diag(2), P1 = diag(0, 2)), data = mcycle)
model$T[1, 2, ] <- c(diff(mcycle$times), 1)
model$Q[1, 1, ] <- c(diff(mcycle$times), 1)^3/3
model$Q[1, 2, ] <- model$Q[2, 1, ] <- c(diff(mcycle$times), 1)^2/2
model$Q[2, 2, ] <- c(diff(mcycle$times), 1)
updatefn <- function(pars, model, ...){
model["H"] <- exp(pars[1])
model["Q"] <- model["Q"] * exp(pars[2])
model
}
fit <- fitSSM(model, inits = c(4, 4), updatefn = updatefn, method = "BFGS")
pred <- predict(fit$model, interval = "conf", level = 0.95)
plot(x = mcycle$times, y = mcycle$accel, pch = 19)
lines(x = mcycle$times, y = pred[, 1])
lines(x = mcycle$times, y = pred[, 2], lty = 2)
lines(x = mcycle$times, y = pred[, 3], lty = 2)
## End(Not run)
Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(KFAS)
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/KFAS/KFAS.Rd_%03d_medium.png", width=480, height=480)
> ### Name: KFAS
> ### Title: KFAS: Functions for Exponential Family State Space Models
> ### Aliases: KFAS KFAS-package
>
> ### ** Examples
>
>
> # Example of local level model for Nile series
> # See Durbin and Koopman (2012)
>
> model_Nile <- SSModel(Nile ~
+ SSMtrend(1, Q = list(matrix(NA))), H = matrix(NA))
> model_Nile
Call:
SSModel(formula = Nile ~ SSMtrend(1, Q = list(matrix(NA))), H = matrix(NA))
State space model object of class SSModel
Dimensions:
[1] Number of time points: 100
[1] Number of time series: 1
[1] Number of disturbances: 1
[1] Number of states: 1
Names of the states:
[1] level
Distributions of the time series:
[1] gaussian
Object is a valid object of class SSModel.> model_Nile <- fitSSM(model_Nile, c(log(var(Nile)), log(var(Nile))),
+ method = "BFGS")$model
>
> # Filtering and state smoothing
> out_Nile <- KFS(model_Nile, filtering = "state", smoothing = "state")
> out_Nile
Smoothed values of states and standard errors at time n = 100:
Estimate Std. Error
level 798.4 63.5
>
> # Confidence and prediction intervals for the expected value and the observations.
> # Note that predict uses original model object, not the output from KFS.
> conf_Nile <- predict(model_Nile, interval = "confidence", level = 0.9)
> pred_Nile <- predict(model_Nile, interval = "prediction", level = 0.9)
>
> ts.plot(cbind(Nile, pred_Nile, conf_Nile[, -1]), col = c(1:2, 3, 3, 4, 4),
+ ylab = "Predicted Annual flow", main = "River Nile")
>
>
> # Missing observations, using the same parameter estimates
>
> NileNA <- Nile
> NileNA[c(21:40, 61:80)] <- NA
> model_NileNA <- SSModel(NileNA ~ SSMtrend(1, Q = list(model_Nile$Q)),
+ H = model_Nile$H)
>
> out_NileNA <- KFS(model_NileNA, "mean", "mean")
>
> # Filtered and smoothed states
> ts.plot(NileNA, fitted(out_NileNA, filtered = TRUE), fitted(out_NileNA),
+ col = 1:3, ylab = "Predicted Annual flow",
+ main = "River Nile")
>
>
> # Example of multivariate local level model with only one state
> # Two series of average global temperature deviations for years 1880-1987
> # See Shumway and Stoffer (2006), p. 327 for details
>
> data("GlobalTemp")
>
> model_temp <- SSModel(GlobalTemp ~ SSMtrend(1, Q = NA, type = "common"),
+ H = matrix(NA, 2, 2))
>
> # Estimating the variance parameters
> inits <- chol(cov(GlobalTemp))[c(1, 4, 3)]
> inits[1:2] <- log(inits[1:2])
> fit_temp <- fitSSM(model_temp, c(0.5*log(.1), inits), method = "BFGS")
>
> out_temp <- KFS(fit_temp$model)
>
> ts.plot(cbind(model_temp$y, coef(out_temp)), col = 1:3)
> legend("bottomright",
+ legend = c(colnames(GlobalTemp), "Smoothed signal"), col = 1:3, lty = 1)
>
>
> ## Not run:
> ##D # Seatbelts data
> ##D # See Durbin and Koopman (2012)
> ##D
> ##D model_drivers <- SSModel(log(drivers) ~ SSMtrend(1, Q = list(NA))+
> ##D SSMseasonal(period = 12, sea.type = "trigonometric", Q = NA) +
> ##D log(PetrolPrice) + law, data = Seatbelts, H = NA)
> ##D
> ##D # As trigonometric seasonal contains several disturbances which are all
> ##D # identically distributed, default behaviour of fitSSM is not enough,
> ##D # as we have constrained Q. We can either provide our own
> ##D # model updating function with fitSSM, or just use optim directly:
> ##D
> ##D # option 1:
> ##D ownupdatefn <- function(pars, model){
> ##D model$H[] <- exp(pars[1])
> ##D diag(model$Q[, , 1]) <- exp(c(pars[2], rep(pars[3], 11)))
> ##D model #for optim, replace this with -logLik(model) and call optim directly
> ##D }
> ##D
> ##D fit_drivers <- fitSSM(model_drivers,
> ##D log(c(var(log(Seatbelts[, "drivers"])), 0.001, 0.0001)),
> ##D ownupdatefn, method = "BFGS")
> ##D
> ##D out_drivers <- KFS(fit_drivers$model, smoothing = c("state", "mean"))
> ##D out_drivers
> ##D ts.plot(out_drivers$model$y, fitted(out_drivers), lty = 1:2, col = 1:2,
> ##D main = "Observations and smoothed signal with and without seasonal component")
> ##D lines(signal(out_drivers, states = c("regression", "trend"))$signal,
> ##D col = 4, lty = 1)
> ##D legend("bottomleft", col = c(1, 2, 4), lty = c(1, 2, 1),
> ##D legend = c("Observations", "Smoothed signal", "Smoothed level"))
> ##D
> ##D # Multivariate model with constant seasonal pattern,
> ##D # using the the seat belt law dummy only for the front seat passangers,
> ##D # and restricting the rank of the level component by using custom component
> ##D
> ##D model_drivers2 <- SSModel(log(cbind(front, rear)) ~ -1 +
> ##D log(PetrolPrice) + log(kms) +
> ##D SSMregression(~law, data = Seatbelts, index = 1) +
> ##D SSMcustom(Z = diag(2), T = diag(2), R = matrix(1, 2, 1),
> ##D Q = matrix(1), P1inf = diag(2)) +
> ##D SSMseasonal(period = 12, sea.type = "trigonometric"),
> ##D data = Seatbelts, H = matrix(NA, 2, 2))
> ##D
> ##D # An alternative way for defining the rank deficient trend component:
> ##D
> ##D # model_drivers2 <- SSModel(log(cbind(front, rear)) ~ -1 +
> ##D # log(PetrolPrice) + log(kms) +
> ##D # SSMregression(~law, data = Seatbelts, index = 1) +
> ##D # SSMtrend(degree = 1, Q = list(matrix(0, 2, 2))) +
> ##D # SSMseasonal(period = 12, sea.type = "trigonometric"),
> ##D # data = Seatbelts, H = matrix(NA, 2, 2))
> ##D #
> ##D # Modify model manually:
> ##D # model_drivers2$Q <- array(1, c(1, 1, 1))
> ##D # model_drivers2$R <- model_drivers2$R[, -2, , drop = FALSE]
> ##D # attr(model_drivers2, "k") <- 1L
> ##D # attr(model_drivers2, "eta_types") <- attr(model_drivers2, "eta_types")[1]
> ##D
> ##D
> ##D likfn <- function(pars, model, estimate = TRUE){
> ##D diag(model$H[, , 1]) <- exp(0.5 * pars[1:2])
> ##D model$H[1, 2, 1] <- model$H[2, 1, 1] <-
> ##D tanh(pars[3]) * prod(sqrt(exp(0.5 * pars[1:2])))
> ##D model$R[28:29] <- exp(pars[4:5])
> ##D if(estimate) return(-logLik(model))
> ##D model
> ##D }
> ##D
> ##D fit_drivers2 <- optim(f = likfn, p = c(-8, -8, 1, -1, -3), method = "BFGS",
> ##D model = model_drivers2)
> ##D model_drivers2 <- likfn(fit_drivers2$p, model_drivers2, estimate = FALSE)
> ##D model_drivers2$R[28:29, , 1]%*%t(model_drivers2$R[28:29, , 1])
> ##D model_drivers2$H
> ##D
> ##D out_drivers2 <- KFS(model_drivers2)
> ##D out_drivers2
> ##D ts.plot(signal(out_drivers2, states = c("custom", "regression"))$signal,
> ##D model_drivers2$y, col = 1:4)
> ##D
> ##D # For confidence or prediction intervals, use predict on the original model
> ##D pred <- predict(model_drivers2,
> ##D states = c("custom", "regression"), interval = "prediction")
> ##D
> ##D # Note that even though the intervals were computed without seasonal pattern,
> ##D # PetrolPrice induces seasonal pattern to predictions
> ##D ts.plot(pred$front, pred$rear, model_drivers2$y,
> ##D col = c(1, 2, 2, 3, 4, 4, 5, 6), lty = c(1, 2, 2, 1, 2, 2, 1, 1))
> ## End(Not run)
>
> ## Simulate ARMA(2, 2) process
> set.seed(1)
> y <- arima.sim(n = 1000, list(ar = c(0.8897, -0.4858), ma = c(-0.2279, 0.2488)),
+ innov = rnorm(1000) * sqrt(0.5))
>
>
> model_arima <- SSModel(y ~ SSMarima(ar = c(0, 0), ma = c(0, 0), Q = 1), H = 0)
>
> likfn <- function(pars, model, estimate = TRUE){
+ tmp <- try(SSMarima(artransform(pars[1:2]), artransform(pars[3:4]),
+ Q = exp(pars[5])), silent = TRUE)
+ if(!inherits(tmp, "try-error")){
+ model["T", "arima"] <- tmp$T
+ model["R", "arima"] <- tmp$R
+ model["P1", "arima"] <- tmp$P1
+ model["Q", "arima"] <- tmp$Q
+ if(estimate){
+ -logLik(model)
+ } else model
+ } else {
+ if(estimate){
+ 1e100
+ } else model
+ }
+ }
>
> fit_arima <- optim(par = c(rep(0, 4), log(1)), fn = likfn, method = "BFGS",
+ model = model_arima)
> model_arima <- likfn(fit_arima$par, model_arima, FALSE)
>
> # AR coefficients:
> model_arima$T[2:3, 2, 1]
arima1 arima2
1.0407787 -0.5733339
> # MA coefficients:
> model_arima$R[3:4]
[1] -0.4199592 0.2038408
> # sigma2:
> model_arima$Q[1]
[1] 0.5370856
> # intercept
> KFS(model_arima)
Smoothed values of states and standard errors at time n = 1000:
Estimate Std. Error
(Intercept) -0.0267343 0.0341194
arima1 0.4740395 0.0341194
arima2 -0.0003022 0.0245714
arima3 -0.0402416 0.0047250
> # same with arima:
> arima(y, c(2, 0, 2))
Call:
arima(x = y, order = c(2, 0, 2))
Coefficients:
ar1 ar2 ma1 ma2 intercept
1.0442 -0.5752 -0.4243 0.2028 -0.0267
s.e. 0.0823 0.0446 0.0901 0.0542 0.0340
sigma^2 estimated as 0.5365: log likelihood = -1107.94, aic = 2227.89
> # small differences because the intercept is handled differently in arima
>
> ## Not run:
> ##D # Poisson model
> ##D # See Durbin and Koopman (2012)
> ##D model_van <- SSModel(VanKilled ~ law + SSMtrend(1, Q = list(matrix(NA)))+
> ##D SSMseasonal(period = 12, sea.type = "dummy", Q = NA),
> ##D data = Seatbelts, distribution = "poisson")
> ##D
> ##D # Estimate variance parameters
> ##D fit_van <- fitSSM(model_van, c(-4, -7), method = "BFGS")
> ##D
> ##D model_van <- fit_van$model
> ##D
> ##D # use approximating model, gives posterior modes
> ##D out_nosim <- KFS(model_van, nsim = 0)
> ##D # State smoothing via importance sampling
> ##D out_sim <- KFS(model_van, nsim = 1000)
> ##D
> ##D out_nosim
> ##D out_sim
> ## End(Not run)
>
> ##########################################################
> ### Examples of generalized linear modelling with KFAS ###
> ##########################################################
>
> # Same example as in ?glm
> counts <- c(18, 17, 15, 20, 10, 20, 25, 13, 12)
> outcome <- gl(3, 1, 9)
> treatment <- gl(3, 3)
> glm_D93 <- glm(counts ~ outcome + treatment, family = poisson())
>
> model_D93 <- SSModel(counts ~ outcome + treatment,
+ distribution = "poisson")
>
> out_D93 <- KFS(model_D93)
> coef(out_D93, last = TRUE)
(Intercept) outcome2 outcome3 treatment2 treatment3
3.044522e+00 -4.542553e-01 -2.929871e-01 5.412337e-16 2.359224e-16
> coef(glm_D93)
(Intercept) outcome2 outcome3 treatment2 treatment3
3.044522e+00 -4.542553e-01 -2.929871e-01 1.337909e-15 1.421085e-15
>
> summary(glm_D93)$cov.s
(Intercept) outcome2 outcome3 treatment2 treatment3
(Intercept) 0.02920635 -1.587302e-02 -1.587302e-02 -2.000000e-02 -2.000000e-02
outcome2 -0.01587302 4.087301e-02 1.587302e-02 -8.576956e-18 -7.712748e-18
outcome3 -0.01587302 1.587302e-02 3.714961e-02 -8.559479e-18 -9.415427e-18
treatment2 -0.02000000 -8.576956e-18 -8.559479e-18 4.000000e-02 2.000000e-02
treatment3 -0.02000000 -7.712748e-18 -9.415427e-18 2.000000e-02 4.000000e-02
> out_D93$V[, , 1]
[,1] [,2] [,3] [,4] [,5]
[1,] 0.02920635 -1.587302e-02 -1.587302e-02 -2.000000e-02 -2.000000e-02
[2,] -0.01587302 4.087301e-02 1.587302e-02 6.938894e-18 1.387779e-17
[3,] -0.01587302 1.587302e-02 3.714961e-02 1.387779e-17 2.775558e-17
[4,] -0.02000000 6.938894e-18 1.387779e-17 4.000000e-02 2.000000e-02
[5,] -0.02000000 1.387779e-17 2.775558e-17 2.000000e-02 4.000000e-02
>
> # approximating model as in GLM
> out_D93_nosim <- KFS(model_D93, smoothing = c("state", "signal", "mean"))
>
> # with importance sampling. Number of simulations is too small here,
> # with large enough nsim the importance sampling actually gives
> # very similar results as the approximating model in this case
> set.seed(1)
> out_D93_sim <- KFS(model_D93,
+ smoothing = c("state", "signal", "mean"), nsim = 1000)
>
>
> ## linear predictor
> # GLM
> glm_D93$linear.predictor
1 2 3 4 5 6 7 8
3.044522 2.590267 2.751535 3.044522 2.590267 2.751535 3.044522 2.590267
9
2.751535
> # approximate model, this is the posterior mode of p(theta|y)
> c(out_D93_nosim$thetahat)
[1] 3.044522 2.590267 2.751535 3.044522 2.590267 2.751535 3.044522 2.590267
[9] 2.751535
> # importance sampling on theta, gives E(theta|y)
> c(out_D93_sim$thetahat)
[1] 3.030875 2.573116 2.730998 3.029760 2.572001 2.729883 3.028874 2.571115
[9] 2.728998
>
>
> ## predictions on response scale
> # GLM
> fitted(glm_D93)
1 2 3 4 5 6 7 8
21.00000 13.33333 15.66667 21.00000 13.33333 15.66667 21.00000 13.33333
9
15.66667
> # approximate model with backtransform, equals GLM
> fitted(out_D93_nosim)
Time Series:
Start = 1
End = 9
Frequency = 1
[1] 21.00000 13.33333 15.66667 21.00000 13.33333 15.66667 21.00000 13.33333
[9] 15.66667
> # importance sampling on exp(theta)
> fitted(out_D93_sim)
Time Series:
Start = 1
End = 9
Frequency = 1
[1] 21.01160 13.34296 15.63043 21.00407 13.33207 15.61232 20.97256 13.31926
[9] 15.60615
>
> # prediction variances on link scale
> # GLM
> as.numeric(predict(glm_D93, type = "link", se.fit = TRUE)$se.fit^2)
[1] 0.02920635 0.03833333 0.03460993 0.02920635 0.03833333 0.03460993 0.02920635
[8] 0.03833333 0.03460993
> # approx, equals to GLM results
> c(out_D93_nosim$V_theta)
[1] 0.02920635 0.03833333 0.03460993 0.02920635 0.03833333 0.03460993 0.02920635
[8] 0.03833333 0.03460993
> # importance sampling on theta
> c(out_D93_sim$V_theta)
[1] 0.02852953 0.03607895 0.03669124 0.03017980 0.03668832 0.03660089 0.02889057
[8] 0.03657079 0.03771477
>
>
> # prediction variances on response scale
> # GLM
> as.numeric(predict(glm_D93, type = "response", se.fit = TRUE)$se.fit^2)
[1] 12.880000 6.814815 8.494815 12.880000 6.814815 8.494815 12.880000
[8] 6.814815 8.494815
> # approx, equals to GLM results
> c(out_D93_nosim$V_mu)
[1] 12.880000 6.814815 8.494815 12.880000 6.814815 8.494815 12.880000
[8] 6.814815 8.494815
> # importance sampling on theta
> c(out_D93_sim$V_mu)
[1] 12.598431 6.364534 8.937270 13.157020 6.465788 8.891127 12.624127
[8] 6.419364 9.079155
>
> # A Gamma example modified from ?glm
> # Now with log-link, and identical intercept terms
> clotting <- data.frame(
+ u = c(5,10,15,20,30,40,60,80,100),
+ lot1 = c(118,58,42,35,27,25,21,19,18),
+ lot2 = c(69,35,26,21,18,16,13,12,12))
>
> model_gamma <- SSModel(cbind(lot1, lot2) ~ -1 + log(u) +
+ SSMregression(~ 1, type = "common", remove.intercept = FALSE),
+ data = clotting, distribution = "gamma")
>
> update_shapes <- function(pars, model) {
+ model$u[, 1] <- pars[1]
+ model$u[, 2] <- pars[2]
+ model
+ }
> fit_gamma <- fitSSM(model_gamma, inits = c(1, 1), updatefn = update_shapes,
+ method = "L-BFGS-B", lower = 0, upper = 100)
> logLik(fit_gamma$model)
[1] -58.54985
> KFS(fit_gamma$model)
Smoothed values of states and standard errors at time n = 9:
Estimate Std. Error
log(u).lot1 -0.52379 0.04457
log(u).lot2 -0.65110 0.04454
(Intercept) 5.22358 0.14788
> fit_gamma$model["u", times = 1]
[1] 33.80859 34.18868
>
>
>
> ## Not run:
> ##D ####################################
> ##D ### Linear mixed model with KFAS ###
> ##D ####################################
> ##D
> ##D # example from ?lmer of lme4 pacakge
> ##D data("sleepstudy", package = "lme4")
> ##D
> ##D model_lmm <- SSModel(Reaction ~ Days +
> ##D SSMregression(~ Days, Q = array(0, c(2, 2, 180)),
> ##D P1 = matrix(NA, 2, 2), remove.intercept = FALSE), sleepstudy, H = NA)
> ##D
> ##D # The first 10 time points the third and fouth state
> ##D # defined with SSMregression correspond to the first subject, and next 10 time points
> ##D # are related to second subject and so on.
> ##D
> ##D # need to use ordinary $ assignment as [ assignment operator for SSModel
> ##D # object guards against dimension altering
> ##D model_lmm$T <- array(model_lmm["T"], c(4, 4, 180))
> ##D attr(model_lmm, "tv")[3] <- 1L #needs to be integer type!
> ##D
> ##D # "cut the connection" between the subjects
> ##D times <- seq(10, 180, by = 10)
> ##D model_lmm["T",states = 3:4, times = times] <- 0
> ##D
> ##D # for the first subject the variance of the random effect is defined via P1
> ##D # for others, we use Q
> ##D model_lmm["Q", times = times] <- NA
> ##D
> ##D update_lmm <- function(pars = init, model){
> ##D P1 <- diag(exp(pars[1:2]))
> ##D P1[1, 2] <- pars[3]
> ##D model["P1", states = 3:4] <- model["Q", times = times] <-
> ##D crossprod(P1)
> ##D model["H"] <- exp(pars[4])
> ##D model
> ##D }
> ##D
> ##D inits <- c(0, 0, 0, 3)
> ##D
> ##D fit_lmm <- fitSSM(model_lmm, inits, update_lmm, method = "BFGS")
> ##D out_lmm <- KFS(fit_lmm$model)
> ##D # unconditional covariance matrix of random effects
> ##D fit_lmm$model["P1", states = 3:4]
> ##D
> ##D # conditional covariance matrix of random effects
> ##D # same for each subject and time point due to model structure
> ##D # these differ from the ones obtained from lmer as these are not conditioned
> ##D # on the fixed effects
> ##D out_lmm$V[3:4,3:4,1]
> ## End(Not run)
> ## Not run:
> ##D # Example of Cubic spline smoothing
> ##D # See Durbin and Koopman (2012)
> ##D require("MASS")
> ##D data("mcycle")
> ##D
> ##D model <- SSModel(accel ~ -1 +
> ##D SSMcustom(Z = matrix(c(1, 0), 1, 2),
> ##D T = array(diag(2), c(2, 2, nrow(mcycle))),
> ##D Q = array(0, c(2, 2, nrow(mcycle))),
> ##D P1inf = diag(2), P1 = diag(0, 2)), data = mcycle)
> ##D
> ##D model$T[1, 2, ] <- c(diff(mcycle$times), 1)
> ##D model$Q[1, 1, ] <- c(diff(mcycle$times), 1)^3/3
> ##D model$Q[1, 2, ] <- model$Q[2, 1, ] <- c(diff(mcycle$times), 1)^2/2
> ##D model$Q[2, 2, ] <- c(diff(mcycle$times), 1)
> ##D
> ##D
> ##D updatefn <- function(pars, model, ...){
> ##D model["H"] <- exp(pars[1])
> ##D model["Q"] <- model["Q"] * exp(pars[2])
> ##D model
> ##D }
> ##D
> ##D fit <- fitSSM(model, inits = c(4, 4), updatefn = updatefn, method = "BFGS")
> ##D
> ##D pred <- predict(fit$model, interval = "conf", level = 0.95)
> ##D plot(x = mcycle$times, y = mcycle$accel, pch = 19)
> ##D lines(x = mcycle$times, y = pred[, 1])
> ##D lines(x = mcycle$times, y = pred[, 2], lty = 2)
> ##D lines(x = mcycle$times, y = pred[, 3], lty = 2)
> ## End(Not run)
>
>
>
>
>
>
>
> dev.off()
null device
1
>
|