Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
A function to perform MDR on a dataset using k-fold cross-validation for internal validation.DescriptionDetermines the best MDR model up to a specified size of interaction Usagemdr.cv(data, K, cv, ratio = NULL, equal = "HR", genotype = c(0, 1, 2)) Arguments
DetailsMDR is a non-parametric data-mining approach to variable selection designed to detect gene-gene or gene-environment interactions in case-control studies. This function uses balanced accuracy as the evaluation measure to rank potential models. An overall best model is chosen to minimize balanced accuracy, while also preventing model over-fitting with internal validation. This function uses ValueAn object of class
... WarningMDR is a combinatorial search approach, so considering high-order interactions (i.e. large values for NoteWhen determining the high-risk/low-risk status of a genotype combination, the order of combinations uses the convention that the genotypes of the first locus vary the most, based on the function Author(s)Stacey Winham ReferencesRitchie et al (2001). Multifactor-dimensionality reduction reveals high-order interactions among estrogen-metabolism genes in sporadic breast cancer. Am J Hm Genet 69, 138-147. Hahn LW, Ritchie MD, Moore JH (2003). Multifactor dimensionality reduction software for detecting gene-gene and gene-environment interactions. Bioinformatics 19(3):376-82. Velez et al (2007). A balanced accuracy function for epistasis modeling in imbalanced datasets using multifactor dimensionality reduction. Genet Epidemiol 31, 306-315. Motsinger AA, Ritchie MD (2006). The effect of reduction in cross-validation intervals on the performance of multifactor dimensionality reduction. Genet Epidemiol 30(6):546-55. See Also
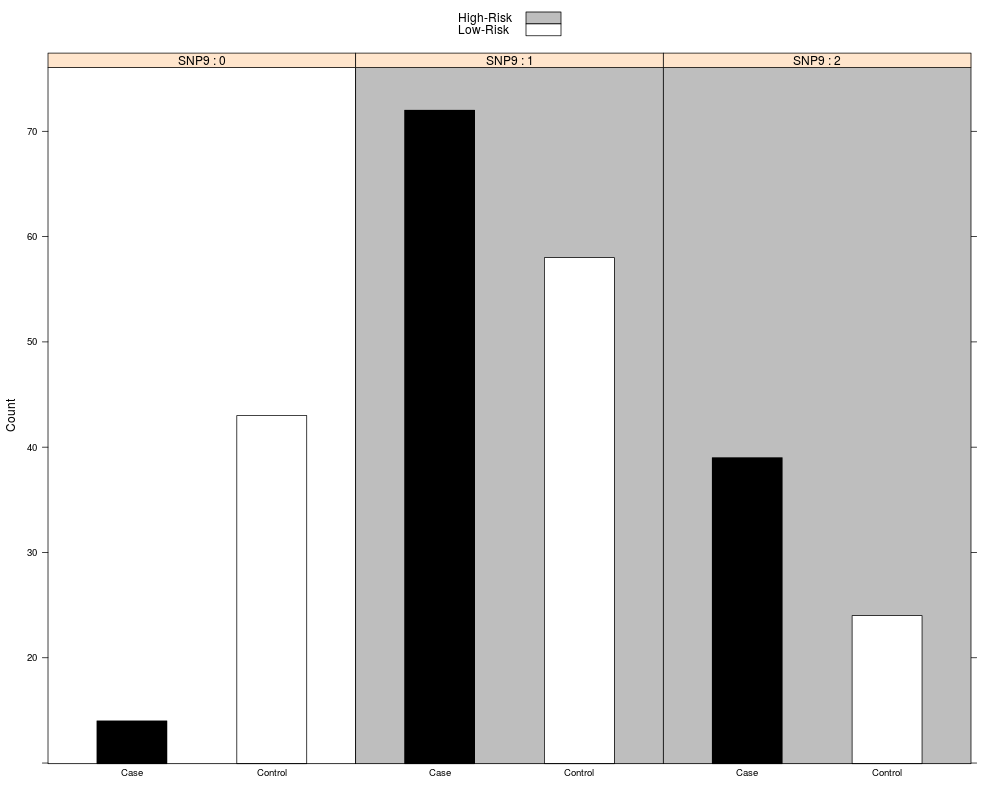
Examples#load test data data(mdr1) fit<-mdr.cv(data=mdr1[,1:11], K=2, cv=5, ratio = NULL, equal = "HR", genotype = c(0, 1, 2)) #fit MDR with 5-fold cross-validation to a subset of the sample data, allowing for 1 to 2-way interactions print(fit) #view the fitted mdr object summary(fit) #create summary table of best MDR model plot(fit, data=mdr1) #create contingency plot of best MDR model; may need to expand the plot window for large values of K Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(MDR)
Loading required package: lattice
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/MDR/mdr.cv.Rd_%03d_medium.png", width=480, height=480)
> ### Name: mdr.cv
> ### Title: A function to perform MDR on a dataset using k-fold
> ### cross-validation for internal validation.
> ### Aliases: mdr.cv
>
> ### ** Examples
>
> #load test data
> data(mdr1)
>
> fit<-mdr.cv(data=mdr1[,1:11], K=2, cv=5, ratio = NULL, equal = "HR", genotype = c(0, 1, 2)) #fit MDR with 5-fold cross-validation to a subset of the sample data, allowing for 1 to 2-way interactions
>
> print(fit) #view the fitted mdr object
$`final model`
[,1] [,2]
[1,] 4 9
$`final model accuracy`
prediction accuracy
64.35354
$`top models`
$`top models`[[1]]
[,1]
[1,] 9
$`top models`[[2]]
[,1] [,2]
[1,] 4 9
$`top model accuracies`
classification accuracy prediction accuracy cross-validation consistency
[1,] 62.29951 59.03734 4
[2,] 67.28735 64.35354 5
$`high-risk/low-risk`
[1] 0 0 1 0 1 1 0 1 1
$genotypes
[1] 0 1 2
$`validation method`
[1] "CV"
attr(,"class")
[1] "mdr"
>
> summary(fit) #create summary table of best MDR model
Level Best Models Classification Accuracy Prediction Accuracy
1 9 62.30 59.04
* 2 4 9 67.29 64.35
Cross-Validation Consistency
4
* 5
'*' indicates overall best model>
> plot(fit, data=mdr1) #create contingency plot of best MDR model; may need to expand the plot window for large values of K
>
>
>
>
>
>
> dev.off()
null device
1
>
|