Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
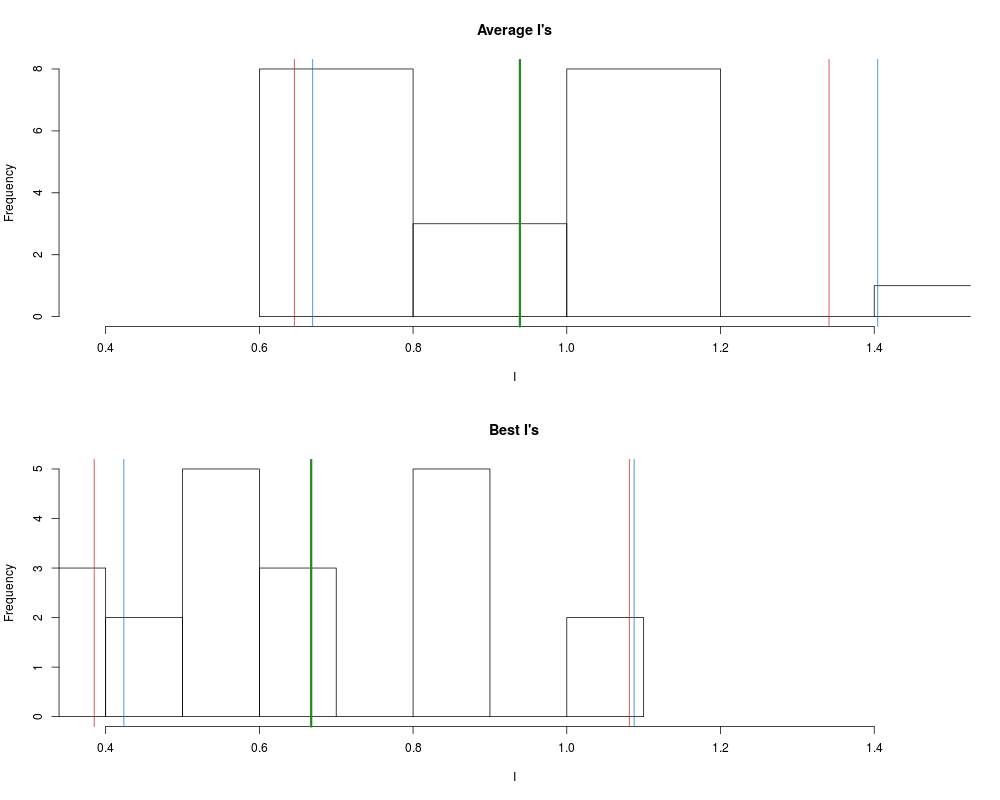
Bootstrap inference for prespecified modelsDescriptionRuns B bootstrap samples using a prespecified model then computes the two I estimates based on cross validation. p values of the two I estimates are computed for a given H_0: mu_I_0 = mu_0 and confidence intervals are provided. Usage
bootstrap_inference(X, y,
model_string,
predict_string = "predict(mod, obs_left_out)",
cleanup_mod_function = NA,
y_higher_is_better = TRUE,
verbose = TRUE,
full_verbose = FALSE,
H_0_mu_equals = 0,
pct_leave_out = 0.10,
B = 3000,
alpha = 0.05,
plot = TRUE,
num_cores = 1,
...)
Arguments
ValueReturns a list object containing results of the procedure. Author(s)Adam Kapelner and Justin Bleich ReferencesKapelner, A, Bleich, J, Cohen, ZD, DeRubeis, RJ and Berk, R (2014) Inference for Treatment Regime Models in Personalized Medicine, arXiv Examplesbeta0 = 1 beta1 = -1 gamma0 = 0 gamma1 = sqrt(2 * pi) mu_x = 0 sigsq_x = 1 sigsq_e = 1 num_boot = 20 #for speed only n = 50 #for speed only x = sort(rnorm(n, mu_x, sigsq_x)) noise = rnorm(n, 0, sigsq_e) treatment = sample(c(rep(1, n / 2), rep(0, n / 2))) y = beta0 + beta1 * x + treatment * (gamma0 + gamma1 * x) + noise X = data.frame(treatment, x) res = bootstrap_inference(X, y, "lm(y ~ . + treatment * ., data = Xyleft)", num_cores = 1, B = num_boot) Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(PTE)
Loading required package: doParallel
Loading required package: foreach
Loading required package: iterators
Loading required package: parallel
Welcome to PTE v1.0 by Adam Kapelner and Justin Bleich
> png(filename="/home/ddbj/snapshot/RGM3/R_CC/result/PTE/bootstrap_inference.Rd_%03d_medium.png", width=480, height=480)
> ### Name: bootstrap_inference
> ### Title: Bootstrap inference for prespecified models
> ### Aliases: bootstrap_inference
>
> ### ** Examples
>
> beta0 = 1
> beta1 = -1
> gamma0 = 0
> gamma1 = sqrt(2 * pi)
> mu_x = 0
> sigsq_x = 1
> sigsq_e = 1
> num_boot = 20 #for speed only
> n = 50 #for speed only
>
> x = sort(rnorm(n, mu_x, sigsq_x))
> noise = rnorm(n, 0, sigsq_e)
>
> treatment = sample(c(rep(1, n / 2), rep(0, n / 2)))
> y = beta0 + beta1 * x + treatment * (gamma0 + gamma1 * x) + noise
>
> X = data.frame(treatment, x)
>
> res = bootstrap_inference(X, y,
+ "lm(y ~ . + treatment * ., data = Xyleft)",
+ num_cores = 1,
+ B = num_boot)
>
>
>
>
>
> dev.off()
null device
1
>
|