Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
class "DAVIDTermClusterDescriptionThis class represents the output of a DAVID Functional Annotation Clustering report. TypeThis class is a " Extends
Slotsthe ones inherited from DAVIDCluster. Methods
Author(s)Cristobal Fresno and Elmer A Fernandez References
See AlsoOther DAVIDTermCluster:
Examples
{
##Load the Gene Functional Classification Tool file report for the
##input demo file 2 to create a DAVIDGeneCluster object.
setwd(tempdir())
fileName<-system.file("files/termClusterReport2.tab.tar.gz",
package="RDAVIDWebService")
untar(fileName)
davidTermCluster2<-DAVIDTermCluster(untar(fileName, list=TRUE))
davidTermCluster2
##Now we can invoke DAVIDCluster ancestor functions to inspect the report
##data, of each cluster. For example, we can call summary to get a general
##idea, and the inspect the cluster with higher Enrichment Score, to see
##which members belong to it, etc. Or simply returning the whole cluster as a
##list with EnrichmentScore and Members.
summary(davidTermCluster2)
higherEnrichment<-which.max(enrichment(davidTermCluster2))
clusterGenes<-members(davidTermCluster2)[[higherEnrichment]]
wholeCluster<-cluster(davidTermCluster2)[[higherEnrichment]]
##Then, we can obtain the ids of the term members calling clusterGenes object
##which is a DAVIDFunctionalAnnotationChart class or directly using ids on
##davidTermCluster2 for the higherEnrichment cluster.
ids(clusterGenes)
ids(davidTermCluster2)[[higherEnrichment]]
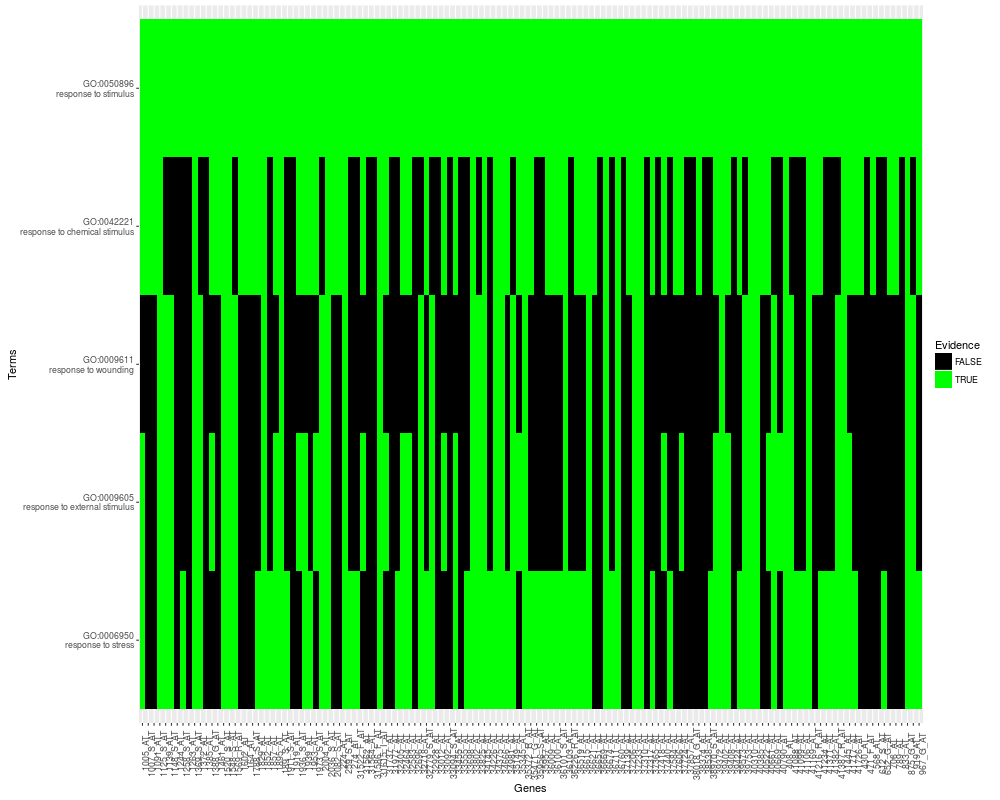
##Finally, we can inspect a 2D tile membership plot, to visual inspect for
##overlapping of genes across the term members of the selected cluster.
plot2D(davidTermCluster2, number=higherEnrichment)
}
Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(RDAVIDWebService)
Loading required package: graph
Loading required package: BiocGenerics
Loading required package: parallel
Attaching package: 'BiocGenerics'
The following objects are masked from 'package:parallel':
clusterApply, clusterApplyLB, clusterCall, clusterEvalQ,
clusterExport, clusterMap, parApply, parCapply, parLapply,
parLapplyLB, parRapply, parSapply, parSapplyLB
The following objects are masked from 'package:stats':
IQR, mad, xtabs
The following objects are masked from 'package:base':
Filter, Find, Map, Position, Reduce, anyDuplicated, append,
as.data.frame, cbind, colnames, do.call, duplicated, eval, evalq,
get, grep, grepl, intersect, is.unsorted, lapply, lengths, mapply,
match, mget, order, paste, pmax, pmax.int, pmin, pmin.int, rank,
rbind, rownames, sapply, setdiff, sort, table, tapply, union,
unique, unsplit
Loading required package: GOstats
Loading required package: Biobase
Welcome to Bioconductor
Vignettes contain introductory material; view with
'browseVignettes()'. To cite Bioconductor, see
'citation("Biobase")', and for packages 'citation("pkgname")'.
Loading required package: Category
Loading required package: stats4
Loading required package: AnnotationDbi
Loading required package: IRanges
Loading required package: S4Vectors
Attaching package: 'S4Vectors'
The following objects are masked from 'package:base':
colMeans, colSums, expand.grid, rowMeans, rowSums
Loading required package: Matrix
Attaching package: 'Matrix'
The following object is masked from 'package:S4Vectors':
expand
Attaching package: 'GOstats'
The following object is masked from 'package:AnnotationDbi':
makeGOGraph
Loading required package: ggplot2
Attaching package: 'RDAVIDWebService'
The following object is masked from 'package:AnnotationDbi':
species
The following object is masked from 'package:IRanges':
members
The following objects are masked from 'package:BiocGenerics':
counts, species
> png(filename="/home/ddbj/snapshot/RGM3/R_BC/result/RDAVIDWebService/DAVIDTermCluster-class.Rd_%03d_medium.png", width=480, height=480)
> ### Name: DAVIDTermCluster-class
> ### Title: class "DAVIDTermCluster
> ### Aliases: DAVIDTermCluster-class
> ### Keywords: classes
>
> ### ** Examples
>
> {
+ ##Load the Gene Functional Classification Tool file report for the
+ ##input demo file 2 to create a DAVIDGeneCluster object.
+ setwd(tempdir())
+ fileName<-system.file("files/termClusterReport2.tab.tar.gz",
+ package="RDAVIDWebService")
+ untar(fileName)
+ davidTermCluster2<-DAVIDTermCluster(untar(fileName, list=TRUE))
+ davidTermCluster2
+
+ ##Now we can invoke DAVIDCluster ancestor functions to inspect the report
+ ##data, of each cluster. For example, we can call summary to get a general
+ ##idea, and the inspect the cluster with higher Enrichment Score, to see
+ ##which members belong to it, etc. Or simply returning the whole cluster as a
+ ##list with EnrichmentScore and Members.
+ summary(davidTermCluster2)
+ higherEnrichment<-which.max(enrichment(davidTermCluster2))
+ clusterGenes<-members(davidTermCluster2)[[higherEnrichment]]
+ wholeCluster<-cluster(davidTermCluster2)[[higherEnrichment]]
+
+ ##Then, we can obtain the ids of the term members calling clusterGenes object
+ ##which is a DAVIDFunctionalAnnotationChart class or directly using ids on
+ ##davidTermCluster2 for the higherEnrichment cluster.
+ ids(clusterGenes)
+ ids(davidTermCluster2)[[higherEnrichment]]
+
+ ##Finally, we can inspect a 2D tile membership plot, to visual inspect for
+ ##overlapping of genes across the term members of the selected cluster.
+ plot2D(davidTermCluster2, number=higherEnrichment)
+ }
>
>
>
>
>
> dev.off()
null device
1
>
|