Supported by Dr. Osamu Ogasawara and  . . |
|
Last data update: 2014.03.03 |
Construction of the superclusters and the one-to-one mapping between themDescription
Usage
SCmapping(clustering1, clustering2, plotting = TRUE, h.min = 0.1, line.wd = 3,
point.sz = 3, offset = 0.1, evenly = TRUE, horiz = FALSE, max.iter =24,
node.col = NULL, edge.col = NULL,...)
Arguments
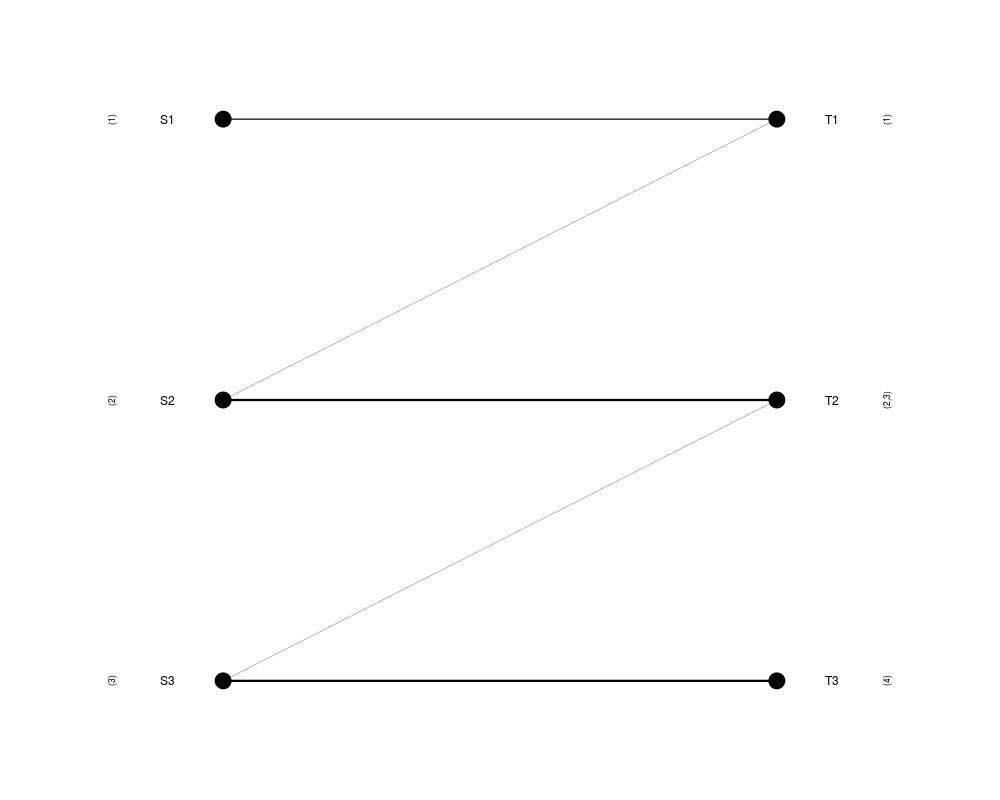
DetailsThe one-to-one mapping between groups of clusters from two different flat partitionings is computed with a greedy algorithm: firstly, for each node the edge with the highest weight is taken, and secondly, the connected components in the edge-reduced bi-graph are found, so that each connected component corresponds to a pair of superclusters with a large overlap. Valuea list containing:
Author(s)Aurora Torrente aurora@ebi.ac.uk and Alvis Brazma brazma@ebi.ac.uk ReferencesTorrente, A. et al. (2005). A new algorithm for comparing and visualizing relationships between hierarchical and flat gene expression data clusterings. Bioinformatics, 21 (21), 3993-3999. See Alsobarycentre, flatVSflat, flatVShier Examples
### computation and visualisation of superclusters
# simulated data
clustering1 <- c(rep(1, 5), rep(2, 10), rep(3, 10))
clustering2 <- c(rep(1, 6), rep(2, 6), rep(3, 4), rep(4, 9))
mapping <- SCmapping(clustering1, clustering2)
Results
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(clustComp)
> png(filename="/home/ddbj/snapshot/RGM3/R_BC/result/clustComp/SCmapping.Rd_%03d_medium.png", width=480, height=480)
> ### Name: SCmapping
> ### Title: Construction of the superclusters and the one-to-one mapping
> ### between them
> ### Aliases: SCmapping
> ### Keywords: clustering comparison
>
> ### ** Examples
>
> ### computation and visualisation of superclusters
> # simulated data
> clustering1 <- c(rep(1, 5), rep(2, 10), rep(3, 10))
> clustering2 <- c(rep(1, 6), rep(2, 6), rep(3, 4), rep(4, 9))
> mapping <- SCmapping(clustering1, clustering2)
>
>
>
>
>
> dev.off()
null device
1
>
|